

Translator官网
所有语言:文字、语音或输入以翻译并打破语言障碍

Translator简介
需求人群:
旅行、学习、商务、医疗
产品特色:
实时文本翻译
图片翻译
文本转语音
切换语言
免费翻译
收藏翻译
Translator官网入口网址
https://play.google.com/store/apps/details
小编发现Translator网站非常受用户欢迎,请访问Translator网址入口试用。
所有语言:文字、语音或输入以翻译并打破语言障碍
旅行、学习、商务、医疗
实时文本翻译
图片翻译
文本转语音
切换语言
免费翻译
收藏翻译
https://play.google.com/store/apps/details
小编发现Translator网站非常受用户欢迎,请访问Translator网址入口试用。

构建应用内AI聊天机器人和AI驱动的文本区域

“可以用来在Web应用中快速实现AI助手和AI驱动的文本编辑”
用作增强版的
结合使用应用内Copilot
useMakeCopilotReadable传递应用状态
CopilotTextarea: AI辅助的文本生成和编辑
Copilot Chatbot: 应用内Copilot,可以查看应用的状态
useMakeCopilotReadable: 向Copilot提供状态信息
useMakeCopilotActionable: 允许Copilot代表用户执行操作
https://github.com/CopilotKit/CopilotKit
小编发现CopilotKit网站非常受用户欢迎,请访问CopilotKit网址入口试用。

利用AI从设计稿中快速生成产品需求文档和任务工单

[“产品经理快速生成文档草稿”,”开发团队理解产品设计需求”,”提高跨团队协作效率”]
产品经理可以上传设计稿,一键生成产品需求文档
开发人员可以快速理解产品具体需求
无需手动字字打字,大幅提升工作效率
上传产品设计稿
AI识别设计稿中的信息
生成产品需求文档草稿
生成工程任务工单草稿
支持导出和分享文档
https://productmonkey.ai/
小编发现Product Monkey AI网站非常受用户欢迎,请访问Product Monkey AI网址入口试用。

AI 定制播客

“适用于任何人想要定制化自己听到的播客内容的场景”
一键生成符合你要求的定制播客
提供多样化的主题和内容选择
定制播客时长和深度
https://www.readtrellis.com/bespoke
小编发现Bespoke网站非常受用户欢迎,请访问Bespoke网址入口试用。

AI Background Generator | PhotoRoom是一个使用稳定扩散技术生成无限数量独特背景的AI工具,可以根据用户的要求生成与之匹配的背景图像,适用于设计师、创意人士、社交媒体用户和网站编辑人员等。
网站服务:图像生成,AI工具,免费,背景生成器,图像AI,图像生成,AI工具,免费,背景生成器。

Create product and portrait pictures using only your phone and our AI photo editing tools。 Remove background, change background and showcase products。网站成立于1998年11月21日,该网站属于综合其他行业。
AI Background Generator | PhotoRoom是一个使用稳定扩散技术生成无限数量独特背景的AI工具。它可以根据您的要求生成与您的准确请求完全匹配的背景图像。
1. 生成无限数量的独特背景:AI Background Generator | PhotoRoom使用稳定扩散技术,可以生成无限数量的独特背景图像,满足用户不同的需求。2. 自定义背景要求:用户可以描述他们想要的背景图像,AI Background Generator | PhotoRoom会根据描述生成与之匹配的背景图像。3. 隐私保护:AI Background Generator | PhotoRoom重视用户的隐私,使用cookie来提升用户的浏览体验,并根据用户的偏好提供个性化的广告或内容。
1. 设计师和创意人士:AI Background Generator | PhotoRoom可以帮助设计师和创意人士快速生成独特的背景图像,用于设计作品、广告宣传等。2. 社交媒体用户:AI Background Generator | PhotoRoom可以为社交媒体用户提供各种独特的背景图像,使他们的社交媒体内容更加吸引人。3. 网站编辑人员:AI Background Generator | PhotoRoom可以为网站编辑人员提供各种独特的背景图像,使他们的网站内容更加丰富多样。
https://www.photoroom.com/backgrounds
AI聚合大数据显示,AI Background Generator by PhotoRoom官网非常受用户欢迎,请访问AI Background Generator by PhotoRoom网址入口(https://www.photoroom.com/backgrounds)试用。

Step-Video V2 是上海阶跃星辰智能科技发布的升级版视频生成模型。该版本在多个核心技术领域进行了优化和创新,采用了更高压缩比的VAE模型以及深度优化的DiT架构,引入强化学习算法。能生成复杂的动态场景,如芭蕾舞、空手道等,同时支持丰富的镜头语言和基础文字生成。Step-Video V2还具备出色的人物表情捕捉能力,能细腻呈现光影效果。
复杂运动生成:能流畅地生成复杂动态场景,如芭蕾舞、空手道、羽毛球等运动场景。人物细节刻画:可以细腻呈现真实人物或虚构角色的表情、神态和光影效果。丰富镜头语言:支持推、拉、摇、移等多种镜头运动方式,以及不同景别之间的切换,为视频创作提供更多可能性。基础文字生成:可将文字自然融入视频内容,生成效果显著优于前代模型。语义理解与指令遵循:结合自研多模态理解大模型和视频知识库,能更精准地描述视频内容和镜头语言,生成更贴近真实世界的视频。中英双语输入:支持中英双语输入,进一步拓展了视频生成的应用场景。
高效压缩的 VAE 模型:Step-Video V2 采用了压缩比更高的变分自编码器(VAE)模型,通过空间和时间的高效压缩,在保证视频重构质量的同时,显著降低了计算复杂度,从而大幅提升视频生成的效率。深度优化的 DiT 架构与强化学习:该版本对扩散模型与 Transformer 架构(DiT)进行了深度优化,引入强化学习算法。使视频生成的运动更流畅自然,细节表现力更强,无论是复杂动态场景还是细腻的人物表情,能以更加逼真的方式呈现。

实时文本转图像生成模型

“研究、实验、图像编辑”
使用SDXL Turbo在研究中进行实时文本到图像生成
在图像编辑中使用SDXL Turbo进行实时图像合成
将SDXL Turbo应用于实验室环境,进行文本到图像的实时生成
单步图像输出
实时文本到图像生成
高采样保真度
推理速度显著提高
https://sdxlturbo.ai/
小编发现SDXL Turbo网站非常受用户欢迎,请访问SDXL Turbo网址入口试用。

基于 ChatGPT 的免费智能工具

“智囊 AI 可以用于文案撰写、合规提问检测、会议总结、翻译等多种场景,帮助提高工作效率。”
小明使用智囊 AI 进行文案撰写,提高了工作效率。
小红使用智囊 AI 进行合规提问检测,避免了合同中的问题和风险。
公司使用智囊 AI 进行会议总结,提高了会议效率和质量。
免费智能对话
自主创造和分享智囊
共享有趣有用的对话
文案撰写
合规提问检测
会议总结
翻译
https://zhinang.ai/
小编发现智囊 AI网站非常受用户欢迎,请访问智囊 AI网址入口试用。

WhatsApp中的个人AI助手

“适用于需要获取各类信息时使用,可随时提问或下达指令”
我要去巴黎旅游,给我一些建议
帮我翻译这段文字到英文
找一些关于量子计算的文章
问题解答
文本生成
翻译
网页搜索
https://www.chatgptbuddy.com
小编发现ChatGPTBuddy网站非常受用户欢迎,请访问ChatGPTBuddy网址入口试用。
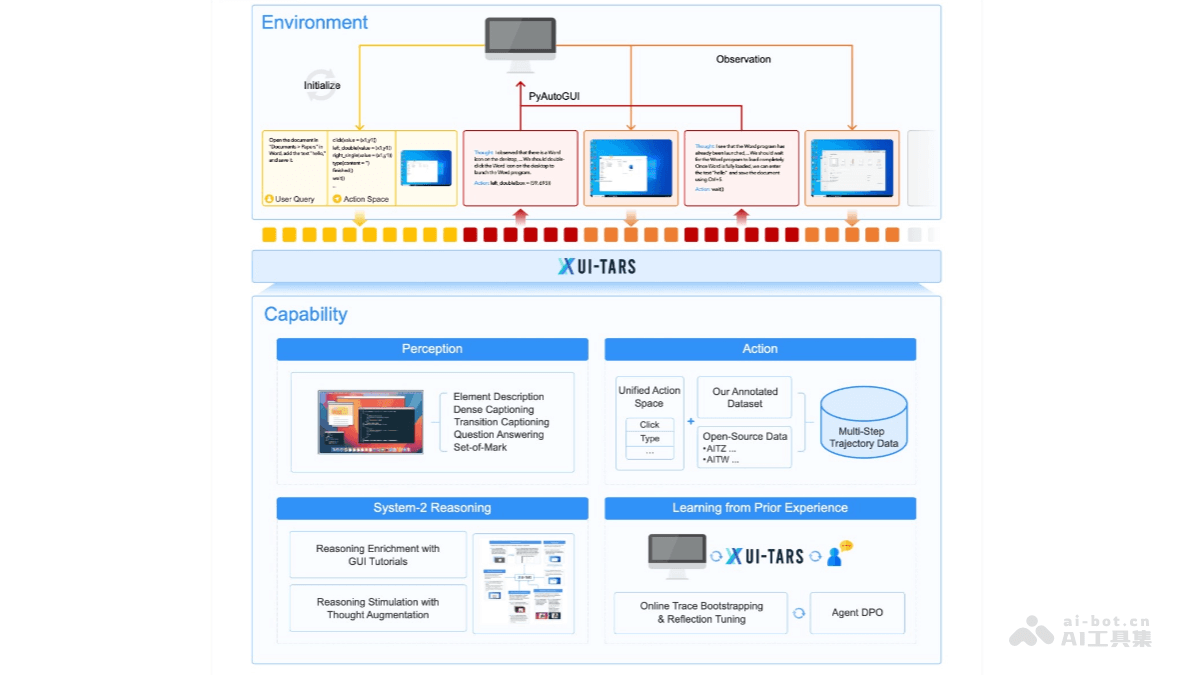
UI-TARS是字节跳动推出的新一代原生图形用户界面(GUI)代理模型,通过自然语言实现对桌面、移动设备和网页界面的自动化交互。具备强大的感知、推理、行动和记忆能力,能实时理解动态界面,通过多模态输入(如文本、图像)执行复杂的任务。 UI-TARS 的核心优势在于跨平台的标准化行动定义,支持桌面、移动和网页等多种环境。结合了快速直观反应和复杂任务规划的能力,支持多步推理、反思和错误纠正。还具备短期和长期记忆功能,能更好地适应动态任务需求。
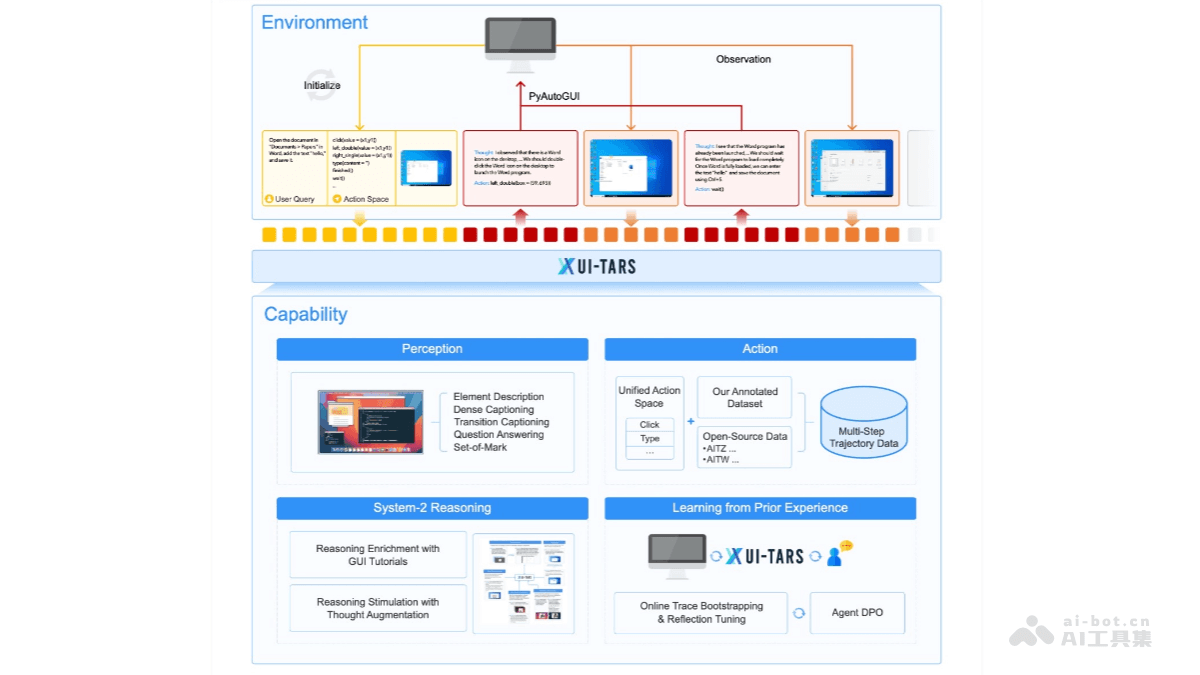
多模态感知:UI-TARS 能处理文本、图像等多种输入形式,实时感知和理解动态界面内容,支持跨平台(桌面、移动、网页)的交互。自然语言交互:用户可以通过自然语言指令与 UI-TARS 对话,完成任务规划、操作执行等复杂任务。支持多步推理和错误纠正,能像人类一样处理复杂的交互场景。跨平台操作:支持桌面、移动和网页环境,提供标准化的行动定义,同时兼容平台特定的操作(如快捷键、手势等)。视觉识别与交互:UI-TARS 能通过截图和视觉识别功能,精准定位界面元素,并执行鼠标点击、键盘输入等操作,适用于复杂的视觉任务。记忆与上下文管理:具备短期和长期记忆能力,能够捕捉任务上下文信息,保留历史交互记录,从而更好地支持连续任务和复杂场景。自动化任务执行:可以自动化完成一系列任务,如打开应用、搜索信息、填写表单等,提高用户的工作效率。灵活部署:支持云端部署(如 Hugging Face 推理端点)和本地部署(如通过 vLLM 或 Ollama),满足不同用户的需求。扩展性:UI-TARS 提供了丰富的 API 和开发工具,方便开发者进行二次开发和集成。
增强感知能力:UI-TARS 使用大规模的 GUI 截图数据集进行训练,能对界面元素进行上下文感知和精准描述。通过视觉编码器实时抽取视觉特征,实现对界面的多模态理解。统一行动建模:UI-TARS 将跨平台操作标准化,定义了一个统一的行动空间,支持桌面、移动端和 Web 平台的交互。通过大规模行动轨迹数据训练,模型能够实现精准的界面元素定位和交互。系统化推理能力:UI-TARS 引入了系统化推理机制,支持多步任务分解、反思思维和里程碑识别等推理模式。能在复杂任务中进行高层次规划和决策。迭代训练与在线反思:解决数据瓶颈问题,UI-TARS 通过自动收集、筛选和反思新的交互轨迹进行迭代训练。在虚拟机上运行,能从错误中学习并适应未预见的情况,减少人工干预。
GitHub仓库:https://github.com/bytedance/UI-TARSHuggingFace模型库:https://huggingface.co/bytedance-research/UI-TARS-7B-DPOarXiv技术论文:https://arxiv.org/pdf/2501.12326
桌面和移动自动化:通过自然语言控制计算机或移动设备,完成任务,如打开应用、搜索信息等。Web 自动化:结合 Midscene.js,开发者可以使用 JavaScript 和自然语言控制浏览器。视觉识别与交互:支持截图和图像识别功能,能够根据视觉信息执行精确的鼠标和键盘操作。