

GPThelp官网
定制化网站聊天机器人

GPThelp简介
需求人群:
“适用于企业网站、电子商务平台等,帮助客户自动获取与网站内容相关的答案。”
使用场景示例:
企业网站客服
电子商务平台在线咨询
新闻网站互动问答
产品特色:
根据网站内容训练聊天机器人
定制设计,改变AI行为
监控对话并修改AI回答
GPThelp官网入口网址
https://gpthelp.ai/zh
小编发现GPThelp网站非常受用户欢迎,请访问GPThelp网址入口试用。
定制化网站聊天机器人
“适用于企业网站、电子商务平台等,帮助客户自动获取与网站内容相关的答案。”
企业网站客服
电子商务平台在线咨询
新闻网站互动问答
根据网站内容训练聊天机器人
定制设计,改变AI行为
监控对话并修改AI回答
https://gpthelp.ai/zh
小编发现GPThelp网站非常受用户欢迎,请访问GPThelp网址入口试用。

快速、准确、易于使用的AI转录服务

AI Transcription Service适用于各种场景,包括内容创作、会议记录、学习笔记、研究分析等。
内容创作者将视频上传至AI Transcription Service,获取视频的文字稿件。
专业人士使用AI Transcription Service将会议录音转录为文字记录。
学生使用AI Transcription Service将课堂讲座录音转录为学习笔记。
快速、准确的音频和视频转录
支持YouTube视频转录
简单易用的界面和操作
https://www.videototextai.com
小编发现Video To Text AI网站非常受用户欢迎,请访问Video To Text AI网址入口试用。

FaceLift是Adobe和加州大学默塞德分校推出的单图像到3D头部模型的转换技术,能从单一的人脸图像中重建出360度的头部模型。FaceLift基于两阶段的流程实现:基于扩散的多视图生成模型从单张人脸图像生成一致的侧面和背面视图;生成的视图被输入到GS-LRM重建器中,产出详细的3D高斯表示。FaceLift能精确保持个体的身份特征,生成具有精细几何和纹理细节的3D头部模型。FaceLift支持视频输入,实现4D新视图合成,能与2D面部重动画技术无缝集成,实现3D面部动画。

单图像3D头部重建:从单张人脸图像中快速、高质量地重建出360度的3D头部模型,包括面部和头发的精细细节。多视图一致性:生成的3D模型在不同视角下保持一致,确保从任何角度查看都具有高质量的视觉效果。身份保持:在重建过程中,准确保持个体的身份特征,即使在生成不可见视图时也能保持高度的身份一致性。4D新视图合成:支持视频输入,实现4D新视图合成,在时间序列上生成一致的3D模型,适用于动态场景。与2D重动画技术集成:与2D面部重动画技术无缝集成,实现3D面部动画,为数字娱乐和虚拟现实应用提供支持。
多视图扩散模型:输入处理:基于图像条件扩散模型,用单张正面人脸图像为输入,生成多个视角的图像,包括侧面和背面视图。扩散模型核心:用Stable Diffusion V2-1-unCLIP模型,基于CLIP图像编码器生成的嵌入作为条件信号,确保生成图像的身份一致性和多视图一致性。多视图注意力机制:基于多视图注意力机制,模型在不同视图之间共享信息,生成多视角一致的RGB图像。GS-LRM重建器:输入融合:将生成的多视图图像及其对应的相机姿态输入到GS-LRM模型中,生成详细的3D高斯表示。3D高斯表示:用3D高斯作为底层表示,特别适合捕捉人类头部的复杂细节,如头发。每个2D像素对应一个3D高斯,参数包括RGB颜色、尺度、旋转四元数、不透明度和射线距离等。变换器架构:GS-LRM采用变换器架构,从一组姿态图像中回归像素对齐的3D高斯,生成详细的3D模型。优化与评估:损失函数:在训练过程中,用MSE和感知损失的组合优化模型,确保生成的3D模型在视觉上与真实图像高度一致。评估指标:用PSNR、SSIM、LPIPS和DreamSim等标准指标评估重建质量,基于ArcFace进行身份保持的评估。
项目官网:https://www.wlyu.me/FaceLift/GitHub仓库:https://github.com/weijielyu/FaceLiftarXiv技术论文:https://arxiv.org/pdf/2412.17812
虚拟现实(VR)和增强现实(AR):创建逼真的3D虚拟角色,提供沉浸式体验,支持实时交互。数字娱乐:生成高质量3D角色模型,用于电影、电视剧、游戏开发和动画制作,提高制作效率和质量。远程存在系统:在视频会议和远程协作中,用3D形式呈现用户,增强交流的自然感和沉浸感。社交媒体和内容创作:生成个性化3D头像,为内容创作者提供工具,丰富创作内容。医疗和教育:生成逼真的3D人体模型,用于医学教育、虚拟手术模拟,及文化遗产保护和虚拟博物馆展示。

将YouTube视频简化为简明摘要

“适用于需要从YouTube视频中快速获取信息的用户,尤其是对学习效率要求较高的人群。”
学生需要快速浏览教育视频内容
研究人员需要从长视频中获取关键信息
对于听力障碍者或偏好阅读的用户
将YouTube视频转换为简明易懂的摘要
提高学习效率
节省时间
减少无关内容干扰
提升内容可访问性
https://www.simplifyextension.com/youtube-summarizer
小编发现Simplify网站非常受用户欢迎,请访问Simplify网址入口试用。

AI语音技术

Speechmatics可以应用于各种场景,包括会议记录、语音识别助手、语音翻译等。
将会议录音转录为文本
实时翻译电话会议
创建语音助手应用
语音转录
实时翻译
https://www.speechmatics.com
小编发现Speechmatics网站非常受用户欢迎,请访问Speechmatics网址入口试用。

一步生成高分辨率图像

[“需要快速生成高分辨图的应用”,”生成具有细节及清晰度的图像”,”可扩展且可定制的生成方案”]
用户输入文本描述,一步生成高质量图像
生成用户指定风格或主题的图像
结合文字生成插件,由故事文本生成配图
一步生成1024px图像
结合渐进式与对抗式蒸馏
开源、兼容LoRA插件
支持风格化或特定主题生成
https://huggingface.co/ByteDance/SDXL-Lightning
小编发现SDXL-Lightning网站非常受用户欢迎,请访问SDXL-Lightning网址入口试用。


Onboardix是一款帮助HR流程数字化的SaaS平台

“Onboardix可用于:- 帮助HR设计角色定制化的入职流程 – 为每位员工提供透明的入职时间轴 – 高效地进行批量入职 – 及时地向候选人发送提醒 – 生成数据驱动的分析见解 – 创建个性化的新员工门户”
HR经理可以为不同部门的员工制定角色特定的入职流程
新员工可以通过员工门户查看个性化的时间轴和资源
ChatGPT机器人可以24小时回答新员工的问题
支持自定义入职流程
提供HR门户和员工门户
内置ChatGPT机器人回答问题
支持批量入职
生成详细的分析报告
https://onboardix.com/
小编发现Onboardix网站非常受用户欢迎,请访问Onboardix网址入口试用。

最佳在线工具,用于从音频文件中分离人声和伴奏。

“音乐人使用AudioStrip来分离人声和伴奏,以便进行混音和后期制作。”
音乐人使用AudioStrip分离人声和伴奏,进行混音
DJ使用AudioStrip分离人声,制作混音
音乐制作人使用AudioStrip进行音频处理
完美的人声分离
多首歌曲的轻松分离
使用AI转录音乐
即时AI母带处理
https://www.audiostrip.co.uk/
小编发现AudioStrip网站非常受用户欢迎,请访问AudioStrip网址入口试用。
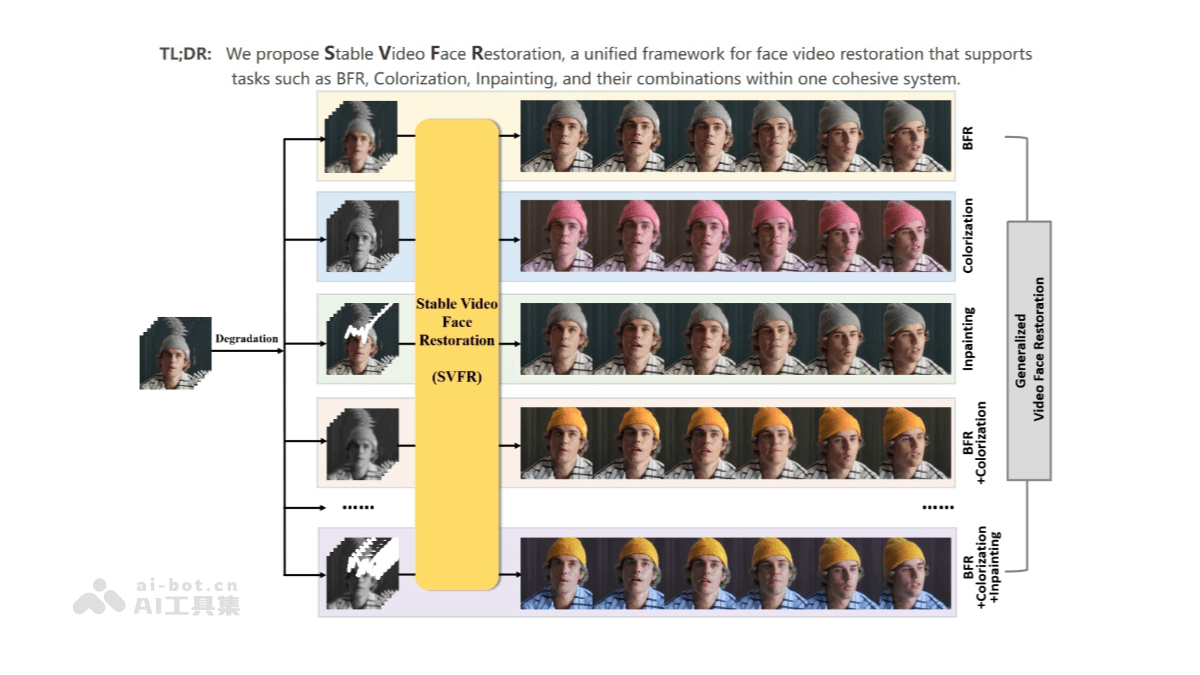
SVFR(Stable Video Face Restoration)是腾讯优图实验室和厦门大学联合推出的用于广义视频人脸修复的统一框架,整合了视频人脸修复(BFR)、着色和修复任务,基于Stable Video Diffusion(SVD)的生成和运动先验,通过统一的人脸修复框架整合特定于任务的信息。SVFR引入了可学习的任务嵌入以增强任务识别,同时采用了一种新颖的统一潜在正则化(ULR)来鼓励不同子任务之间的共享特征表示学习。为了进一步提高恢复质量和时间稳定性,还引入了面部先验学习和自参考细化作为用于训练和推理的辅助策略。
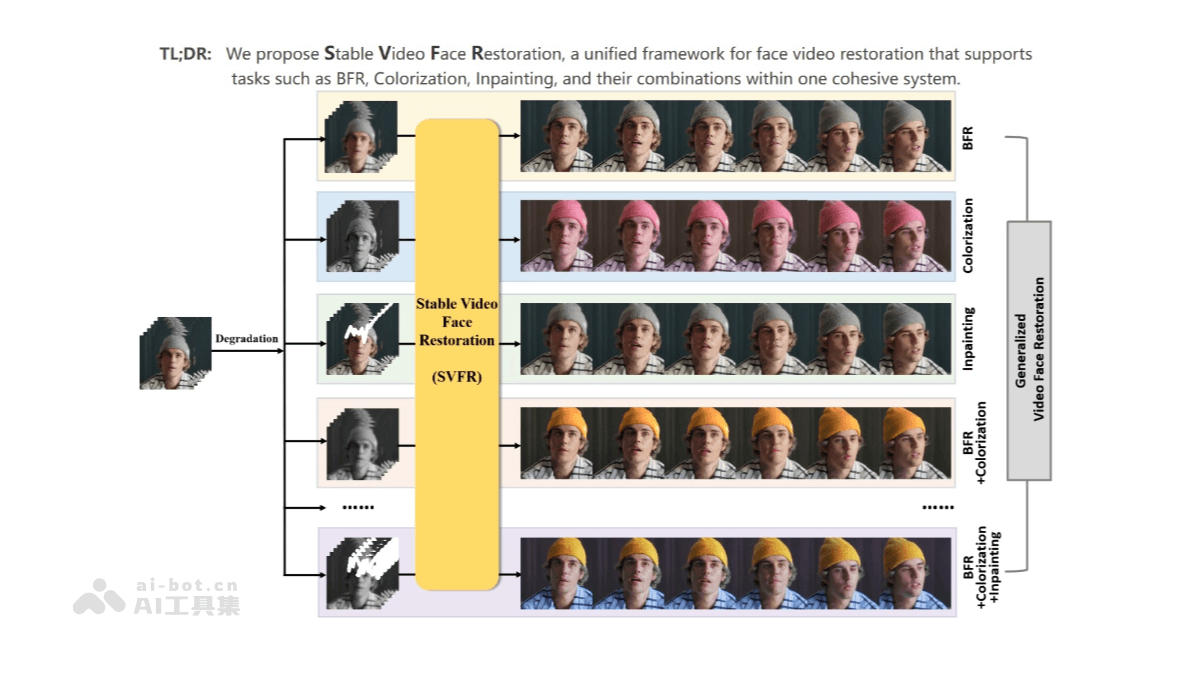
视频人脸修复(BFR):提升视频中人脸的细节和清晰度,使模糊或损坏的人脸画面变得更加清晰和自然。人脸着色:为黑白或色彩失真的视频人脸添加生动的色彩,增强视觉效果。人脸修复(Inpainting):修复视频中人脸的缺失部分,如遮挡或损坏的区域,恢复完整的人脸细节。
任务整合:SVFR整合了视频人脸修复(BFR)、着色和修复任务,通过一个统一的框架来处理这些任务,实现协同增益。这种整合方法可以利用不同任务之间的互补信息,提升整体的修复效果。生成和运动先验:SVFR基于Stable Video Diffusion(SVD)的生成和运动先验,增强修复效果。SVD提供了强大的生成能力和运动信息,帮助模型更好地理解和处理视频中的人脸运动,确保时间连贯性。任务嵌入:引入可学习的任务嵌入,增强模型对特定任务的识别能力。使模型能更好地理解输入数据所属的任务类型,更准确地进行修复。统一潜在正则化(ULR):采用ULR方法,鼓励不同子任务之间的特征共享。通过将不同任务的中间特征整合到一个共享的潜在空间中,ULR有助于模型学习更通用的特征表示,提升修复质量。面部先验学习:为了进一步提高修复质量,SVFR引入了面部先验学习。通过使用面部地标等结构先验,模型可以更自然地嵌入面部结构信息,避免面部结构异常和纹理失真。自引用细化:在推理阶段,SVFR采用自引用细化策略,通过参考之前生成的帧来优化当前帧的修复结果,增强时间稳定性。这种策略确保了视频中人脸的平滑过渡和一致性。
项目官网:https://wangzhiyaoo.github.io/SVFRGithub仓库:https://github.com/wangzhiyaoo/SVFRarXiv技术论文:https://arxiv.org/pdf/2501.01235
影视后期制作:对老旧电影中模糊、损坏的人脸画面进行修复,恢复清晰、自然的人脸细节,提升观影体验。网络视频内容创作:对拍摄条件不佳导致人脸质量差的视频片段进行修复,改善视频整体质量,增强观众吸引力。数字档案修复:对存储时间较长、质量退化的视频档案中的人脸部分进行修复,保留珍贵的历史影像资料。
