
UI-TARS是什么
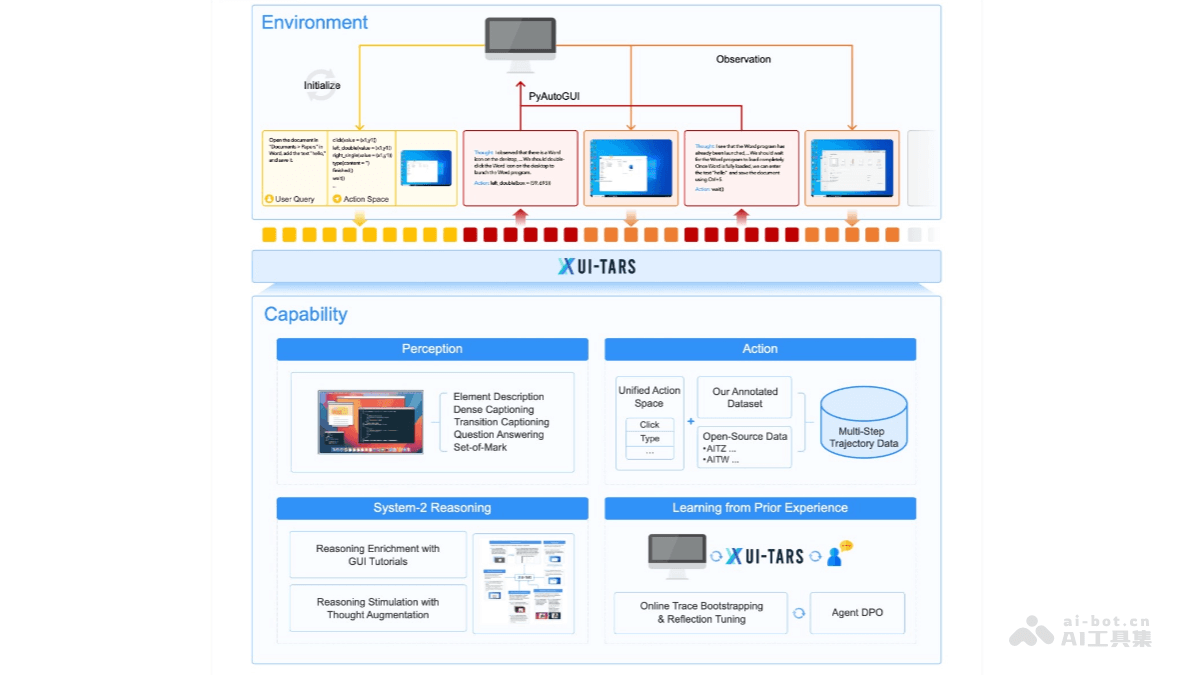
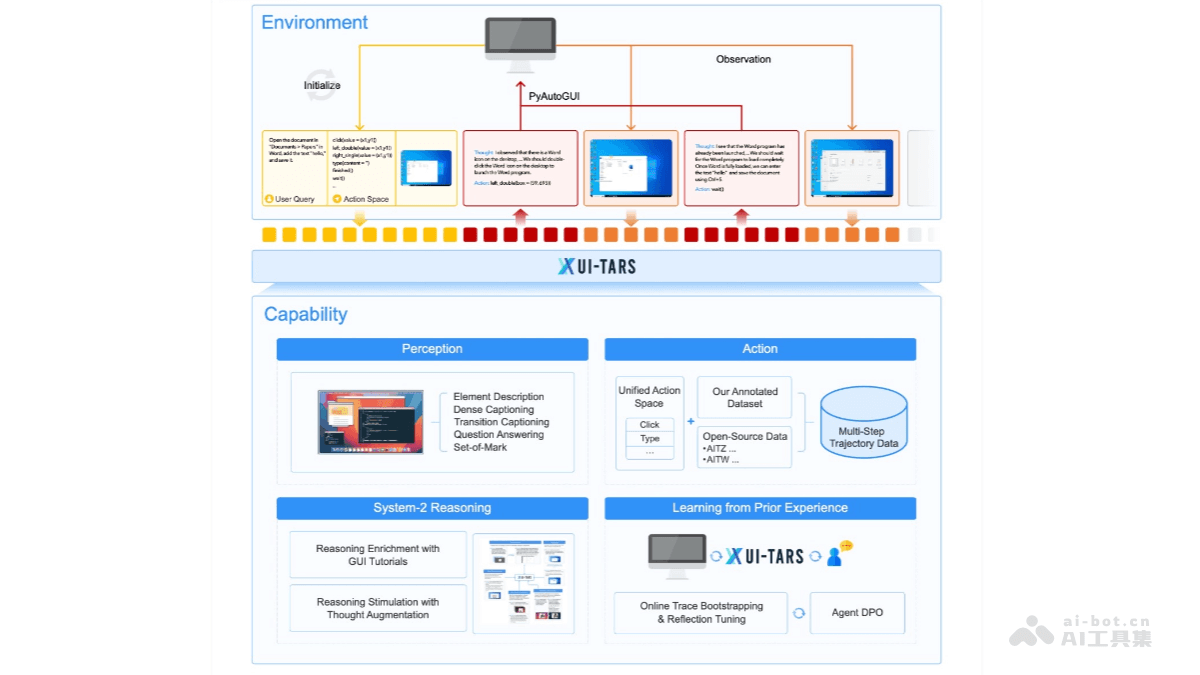
UI-TARS是字节跳动推出的新一代原生图形用户界面(GUI)代理模型,通过自然语言实现对桌面、移动设备和网页界面的自动化交互。具备强大的感知、推理、行动和记忆能力,能实时理解动态界面,通过多模态输入(如文本、图像)执行复杂的任务。 UI-TARS 的核心优势在于跨平台的标准化行动定义,支持桌面、移动和网页等多种环境。结合了快速直观反应和复杂任务规划的能力,支持多步推理、反思和错误纠正。还具备短期和长期记忆功能,能更好地适应动态任务需求。
UI-TARS的主要功能
多模态感知:UI-TARS 能处理文本、图像等多种输入形式,实时感知和理解动态界面内容,支持跨平台(桌面、移动、网页)的交互。自然语言交互:用户可以通过自然语言指令与 UI-TARS 对话,完成任务规划、操作执行等复杂任务。支持多步推理和错误纠正,能像人类一样处理复杂的交互场景。跨平台操作:支持桌面、移动和网页环境,提供标准化的行动定义,同时兼容平台特定的操作(如快捷键、手势等)。视觉识别与交互:UI-TARS 能通过截图和视觉识别功能,精准定位界面元素,并执行鼠标点击、键盘输入等操作,适用于复杂的视觉任务。记忆与上下文管理:具备短期和长期记忆能力,能够捕捉任务上下文信息,保留历史交互记录,从而更好地支持连续任务和复杂场景。自动化任务执行:可以自动化完成一系列任务,如打开应用、搜索信息、填写表单等,提高用户的工作效率。灵活部署:支持云端部署(如 Hugging Face 推理端点)和本地部署(如通过 vLLM 或 Ollama),满足不同用户的需求。扩展性:UI-TARS 提供了丰富的 API 和开发工具,方便开发者进行二次开发和集成。
UI-TARS的技术原理
增强感知能力:UI-TARS 使用大规模的 GUI 截图数据集进行训练,能对界面元素进行上下文感知和精准描述。通过视觉编码器实时抽取视觉特征,实现对界面的多模态理解。统一行动建模:UI-TARS 将跨平台操作标准化,定义了一个统一的行动空间,支持桌面、移动端和 Web 平台的交互。通过大规模行动轨迹数据训练,模型能够实现精准的界面元素定位和交互。系统化推理能力:UI-TARS 引入了系统化推理机制,支持多步任务分解、反思思维和里程碑识别等推理模式。能在复杂任务中进行高层次规划和决策。迭代训练与在线反思:解决数据瓶颈问题,UI-TARS 通过自动收集、筛选和反思新的交互轨迹进行迭代训练。在虚拟机上运行,能从错误中学习并适应未预见的情况,减少人工干预。
UI-TARS的项目地址
GitHub仓库:https://github.com/bytedance/UI-TARSHuggingFace模型库:https://huggingface.co/bytedance-research/UI-TARS-7B-DPOarXiv技术论文:https://arxiv.org/pdf/2501.12326
UI-TARS的应用场景
桌面和移动自动化:通过自然语言控制计算机或移动设备,完成任务,如打开应用、搜索信息等。Web 自动化:结合 Midscene.js,开发者可以使用 JavaScript 和自然语言控制浏览器。视觉识别与交互:支持截图和图像识别功能,能够根据视觉信息执行精确的鼠标和键盘操作。