Moshi 是一个多流实时语音生成 Transformer 模型,支持全双工语音对话。其主要特点是同时语音输入和输出(全双工),以及处理复杂对话场景的能力,包括重叠语音、中断和情绪表达等非语言信息。
这意味着它可以同时听和说,旨在解决传统对话系统中的一些问题,例如延迟、非语言信息(例如情绪)丢失以及对话轮流的僵化结构。
全双工通信:传统的对话系统是回合制的(一个人在另一个人开始之前结束讲话)。 Moshi 突破了这一限制,支持全双工通信。这意味着 Moshi 可以在用户说话时生成语音响应,不受回合限制,并且可以处理复杂的对话动态,例如重叠语音、中断和快速反馈。
多流处理:Moshi 通过处理多个音频流来实现同时收听和生成语音。这种多流架构使其能够灵活处理用户和系统之间的语音交互,而不会中断对话的自然流程。
相比传统的语音对话系统, Moshi 有几个显着的优势:
实时响应:Moshi的响应速度非常快,延迟仅为160-200毫秒,接近自然对话中的反应速度,因此可以提供更流畅的对话体验。
语音到语音处理:传统系统通常依赖于语音到文本到语音的过程,而 Moshi 可以直接处理语音输入并生成语音输出,保留语气和情绪等非语言信息。
全双工对话:Moshi不依赖于严格的对话轮流,而是可以同时处理用户和系统语音,这意味着它可以处理重叠语音和中断,更接近人类对话的自然形式。
Moshi 的主要特点:
实时语音对话:Moshi 直接从音频输入生成音频输出,而不是依赖传统的语音到文本到语音的过程。通过直接处理语音数据,Moshi 保留了语气、情绪、重叠语音和中断等非语言信息,确保对话更加自然和流畅。
全双工通信:Moshi 能够同时听和说,这意味着它可以在用户说话时生成语音响应,而无需严格的对话轮流。它可以处理复杂的对话场景,例如重叠的语音和可以随时插入的不间断反馈(例如“嗯”或“我明白”)。
低延迟:Moshi 的设计延迟非常低,理论上只有 160 毫秒,实际上约为 200 毫秒。这意味着 Moshi 可以近乎实时地响应用户输入,提供更流畅的对话体验。
内心独白法:Moshi 在生成语音之前预测文本标记,这显着提高了生成语音的语言质量和一致性。这不仅使生成的语音更加清晰,还提高了系统在流媒体环境下的语音识别和文本转语音能力。 Moshi通过引入“内心独白”机制,实现了流式语音识别(ASR)和文本转语音(TTS)功能,支持在连续对话流中同时处理语言和音频。
并行处理多个音频流:Moshi 能够同时处理用户和系统的语音流。这种多流处理能力让Moshi不仅能够生成自己的语音,还能实时理解并响应用户的语音。
情绪和言语动态处理:通过直接处理语音而不是中间文本,Moshi 能够理解和生成充满情感的语音,并处理复杂的对话动态,例如情绪表达、声音变化等。
支持复杂的对话动态:Moshi 能够处理自然对话的复杂动态,例如打断、交错、感叹词和响应。传统系统依赖于清晰的对话轮流(一个人在另一个人轮流之前发言),但 Moshi 消除了这一限制,使对话更加自然。
Moshi的模型架构
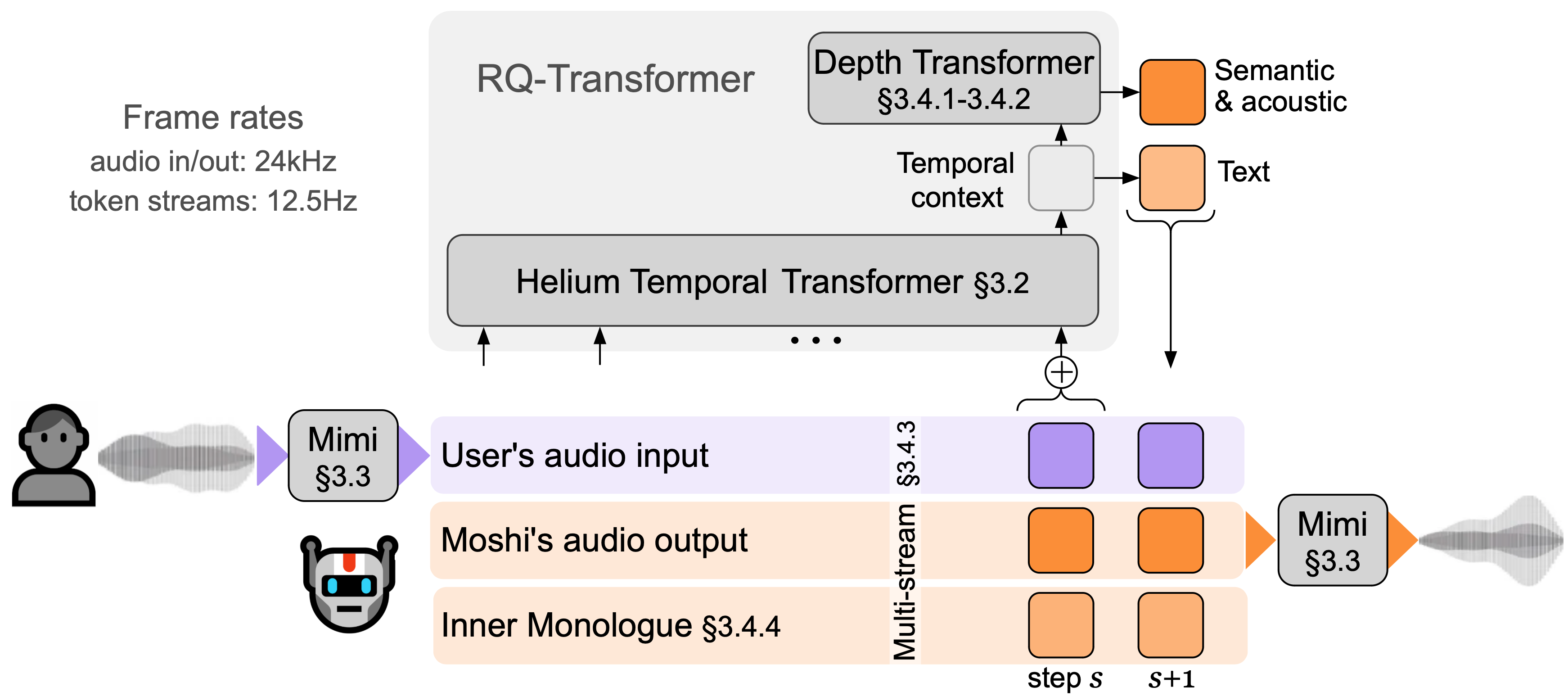
Moshi 由三个主要部分组成: Helium,一个用 2.1 万亿个 token 训练的 7B 语言模型; Mimi,一种对语义和声学信息进行建模的神经音频编解码器;以及新的多流架构,可以分别对用户和 Moshi 的音频进行建模。
通过协同工作,这些模块可以实现流畅的全双工对话、情感表达以及复杂对话动态的处理。
Helium 文本语言模型
氦气是 Moshi 的核心。它是一个基于 Transformer 架构(类似于 GPT)的具有 70 亿个参数的文本语言模型。 Helium为Moshi提供了强大的语言理解和生成能力,能够处理复杂的文本推理和对话任务。
其训练数据包括 2.1 万亿个英语单词,赋予其广泛的知识和语言能力。
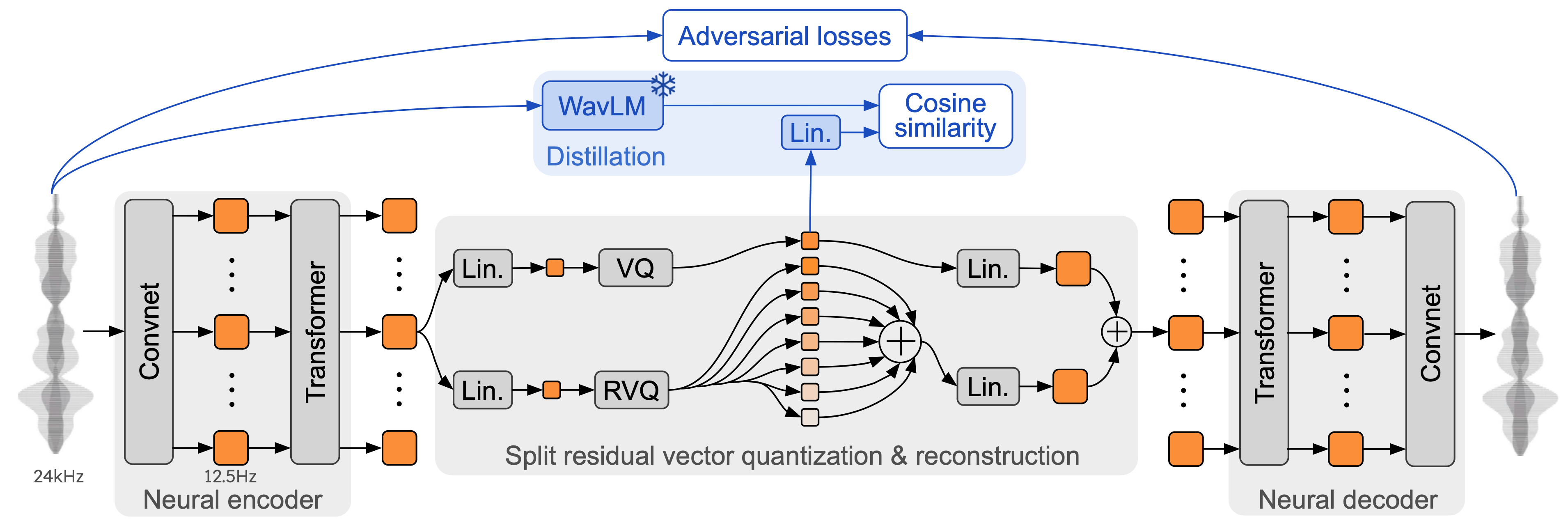
Mimi 神经音频编解码器:Mimi是 Moshi 的音频处理组件。它是一种神经网络音频编解码器,负责将音频转换为离散语音标记,并能够反向生成高质量的语音输出。
Mimi使用残差矢量量化(RVQ)技术将语音数据编码为离散的语音和语义标记,确保高语音保真度和语言一致性。
通过结合语义和声学标记,Mimi 不仅可以生成自然语音,还可以处理复杂的语音上下文和情感信息。
内心独白法:内部独白方法是 Moshi 语音生成的关键技术,它允许模型在生成语音之前预测与音频同步的文本标签。这种方法不仅提高了生成语音的语言质量,还让Moshi能够在流媒体环境下实现语音识别和文本到语音的转换功能。
同步生成文本和语音:在生成音频之前,Moshi 生成与其语音输出相对应的文本流。该文本流作为语音生成的基础,使语音生成更加准确,有助于处理复杂的对话场景。
流媒体兼容性:这种方法允许 Moshi 处理语音,同时仍然在流媒体环境中实现高效的语音识别和文本转语音 (TTS)。
该模型架构旨在处理多个并行音频流并实时生成语音和文本。 Moshi 可以在处理用户语音的同时生成系统语音,这使其能够支持不间断的自然对话。
Moshi详细技术方法
1. 语音到语音生成架构
Moshi 的核心创新在于将语音对话视为语音到语音的生成任务,而不是传统的文本到语音再到语音的多组件过程。传统的语音对话系统包括语音活动检测(VAD)、语音识别(ASR)、自然语言理解(NLU)、自然语言生成(NLG)和文本转语音(TTS)等多个独立模块。
Moshi 直接生成语音标记,使得语音在理解和生成过程中不依赖于中间文本表示,从而避免了信息(例如情感、语气和非语言声音)的丢失。
2. Helium 文本语言模型
Moshi 基于 Helium 文本语言模型,这是一个具有 7B 参数的大型文本生成模型。 Helium经过2.1万亿英文数据预训练,具有强大的语言理解、推理和生成能力。它是 Moshi 的语义理解基础,支持复杂的自然语言处理功能,包括开放式对话和问答。
氦气的主要特点:
自回归 Transformer 架构:Moshi 基于 Helium,一种基于 Transformer 架构的文本语言模型。与经典的 Transformer 类似,Helium 使用多层注意力机制和自回归建模方法来处理文本输入并生成输出。该模型有7B个参数,足以支持大规模语料库的学习。
RMS归一化:在注意力模块、前馈模块、输出层使用RMS归一化,提高模型的训练稳定性。
旋转位置编码(RoPE) :用于处理较长的上下文窗口(4096 个令牌),以确保模型可以捕获对话中的远程依赖关系。
高效的 FlashAttention :通过优化的注意力计算,长序列输入下的模型推理更加高效。
3.Mimi神经音频编解码器
Mimi 是 Moshi 中用于语音处理的神经音频编解码器。它的任务是将连续的语音信号离散化为音频标记。这些离散的音频标记类似于文本标记,可以表示语音中的详细信息。 Mimi采用残差矢量量化(RVQ)技术,以较低的比特率保留高质量的音频,支持实时语音生成和处理。
咪咪关键技术:
残差矢量量化(RVQ) :Mimi使用多级残差矢量量化将复杂的音频信号离散化为多个级别的音频令牌。这种方法允许每个时间步骤有效地编码语音的语义和声学信息,同时确保音频重建的质量。
语义和声学标记的组合:Mimi 使用的音频标记包括语义和声学信息。语义标记保留语音的内容(例如所说的特定单词),而声学标记则描述语音的音频特征,例如音色、情感和语调。
流式编码和解码:Mimi支持流式传输,可以在实时对话中实现连续的语音生成和识别。这使得Moshi的反应速度非常接近自然对话。
4. RQ-Transformer的架构
Moshi 采用多流分层生成架构,可以并行处理多个音频流。 Moshi 通过同时对用户的语音流和系统自身的语音流进行建模,实现对话中的灵活交互,允许复杂的对话动态,例如说话者之间的交错、中断和感叹词。
这是先前提出的用于离散图像生成的架构,并且可以在不增加 Helium 序列长度的情况下对语义和声学标记的层次结构进行建模。这意味着每一秒的音频只需要通过7B骨干模型12.5次,就可以在L4或M3 Macbook pro上实时运行!与 MusicGen 的令牌延迟相结合,这为音频语言建模提供了最先进的性能。
分层自回归建模:Moshi 使用 RQ-Transformer(Residual Quantizer Transformer)将音频标记分解为多个级别,并通过分层自回归建模生成音频。具体来说,模型首先使用较大的 Temporal Transformer 来处理时间序列,然后使用较小的 Depth Transformer 在每个时间步处理多个子序列。这种设计大大提高了生成长音频序列的效率。
多模态序列生成:模型同时生成多个序列(包括文本、语义标记和音频标记),并通过内部独白机制确保它们在时间上精确对齐。每个时间步生成的内容不仅包含当前语音,还包含相应的文本前缀,使得生成的语音内容在语义上更具逻辑性。
Architecture of RQ-Transformer
5、“内心独白”机制
Moshi的“内心独白”机制是其语音生成的关键创新之一。通过这种机制,Moshi 在生成音频之前预测相应的时间对齐文本标记。这不仅提高了生成语音的语言一致性,还支持实时语音识别(ASR)和文本到语音(TTS)转换。
“内心独白”机制的特点:
对齐的文本和音频生成:Moshi 首先预测文本,然后生成音频,使生成的语音在语法和内容上更加准确和流畅。
延迟机制:通过在文本和音频之间引入延迟,Moshi 可以分别执行 ASR 和 TTS 任务。例如,先生成文本,后生成音频,则模型为TTS模式;否则,处于 ASR 模式。 Moshi 可以在这两种模式之间无缝切换,确保模型既能生成又能识别语音。
Moshi: Delay mechanism
Moshi: TTS mode
6.多流建模
Moshi 的架构允许同时处理多个音频流,既可以监控用户的语音,也可以生成系统自己的语音。在对话过程中,Moshi 可以动态处理音频的重叠部分(例如中断、交错),而无需提前明确划分扬声器轮流。这项技术使对话更加自然。
同步生成语义和声音令牌:Moshi 使用并行语义和音频令牌生成机制,并通过引入时间延迟来优化这些令牌之间的依赖关系。通过对用户和系统的音频流进行精确建模,Moshi能够灵活应对复杂的对话场景。
双流音频处理:Moshi 同时处理用户和系统语音流,并通过并行建模两个自回归音频流来实现全双工会话。这种设计使模型能够应对自然对话中的重叠语音和中断。
语义和音频的延迟对齐:通过在语义标记和音频标记之间引入延迟,确保生成的语音内容连贯且高效。延迟可能是 1 到 2 帧,具体取决于对话动态。
Moshi: Multi-stream modeling
7. 模型训练与微调
大规模预训练:Moshi 的文本语言模型(Helium)通过对超过 2.1 万亿个英文 token 的预训练,拥有丰富的语言理解和生成能力。该模型经过大规模文本和语音数据的训练,可以处理各种复杂的对话场景。
无监督和有监督多阶段训练:Moshi首先对大规模无监督语音数据进行预训练,然后对包含自然对话的多流数据进行后训练,最后进行指令微调,使其在实际对话中表现更好。
Helium预训练:首先,在大规模文本数据集上预训练Helium文本语言模型,以提高其语言理解和推理能力。
Moshi 预训练:在未标记的音频数据集上训练多流音频模型,以学习处理语音生成和语义理解。
多流微调:使用Fisher数据集(包含两路语音对话数据)对模型进行微调,提高其处理多流语音输入的能力。
指令微调:最后利用生成的指令对话数据进行微调,以增强模型在自然对话场景下的性能。
数据增强:在训练过程中,Moshi使用了数据增强技术,例如添加背景噪声、模拟用户回声等,使模型能够在不同的语音环境下稳定表现,增强其鲁棒性。
Moshi的性能评估
1. 语音生成的质量和一致性
语音清晰度:Moshi 在语音生成方面表现出色,实验表明它可以生成高质量且易于理解的语音。它可以在生成过程中保持语音连贯性,尤其是在长对话中,这是复杂上下文中对话模型的重要性能指标。
语音的自然性和一致性:通过使用Mimi神经音频编解码器,Moshi可以生成高保真语音并保持系统语音的一致性。此外,该模型能够根据不同的对话上下文生成适当的情绪语调,提高用户体验的自然度。
2. 实时响应性能
低延迟:Moshi的延迟理论上为160毫秒,实际测试约为200毫秒。这意味着Moshi可以近乎实时地响应用户输入,显着提高交互的流畅度和用户的对话体验。
全双工通信能力:Moshi在测试中展示了其同时接收和生成语音的能力。这种全双工功能使其能够处理重叠语音和对话中断,显示出接近自然人类对话的响应速度。
3. 语音识别和对话理解
自动语音识别(ASR) :通过内部独白方法,Moshi 将文本和语音流结合起来,显着提高语音识别的准确性。该模型不仅捕获用户的语音输入,还通过首先生成文本预测来增强系统的响应准确性。
对话理解和推理能力:Moshi使用Helium语言模型进行文本理解和推理,这使得它在处理复杂问题、开放式对话和知识问答方面表现良好。实验结果表明,Moshi 可以有效地理解上下文并提供合理的答案。
4. 多流语音处理的鲁棒性
重叠语音处理:Moshi 能够在评估中处理复杂的对话场景,例如多个语音流的重叠对话。这对于现实应用中的多任务处理非常重要,因为自然对话通常会涉及中断和重叠语音。
多上下文对话处理:Moshi 在多个数据流上进行训练,能够在不同的对话场景中表现良好,无论是单个用户的语音流还是同时与多个用户的对话。
5. 问答和知识获取
Moshi 在问答和知识获取任务方面优于当前的其他语音对话系统。凭借强大的文本理解能力和实时语音生成能力,Moshi 可以处理多轮问答,准确提取并回复用户问题。
语言推理和常识问答:该模型能够处理复杂的推理任务,并且在自然语言处理(NLP)的各种标准评估中表现良好,例如常识问答、阅读理解和开放式问答。
6.语音情感与个性化生成
情感语音生成:Moshi 在评估中展示了其生成情感语音的能力。它能够根据对话的上下文生成具有不同情绪的语音输出,例如愤怒、快乐或悲伤。
个性化语音风格:通过训练过程中的指令微调,Moshi可以根据用户需求生成不同风格或特定角色的语音。这种个性化的能力使其在特定的对话场景下表现更加多样化。
7、安全可靠
安全对话评估:Moshi 在处理包含敏感或不适当内容的对话时表现出良好的安全性。它能够有效识别并避免生成不当内容,确保对话的安全性和道德性。
鲁棒性和对噪声环境的适应:在噪声和复杂环境的评估中,Moshi表现出了良好的鲁棒性。通过数据增强技术(例如噪声添加和回声处理),该模型能够应对不同的语音环境,并保证在噪声环境下的高质量输出。
八、综合测试结果
Moshi的综合性能测试表明,其在语音生成、对话理解、实时响应、复杂对话处理等方面取得了领先的成绩。尤其是,Moshi 在处理重叠对话、语音中断、情感产生等方面的表现远远超过传统对话系统。
技术报告: https://kyutai.org/Moshi.pdf
GitHub: https://github.com/kyutai-labs/moshi
模型下载: https ://huggingface.co/collections/kyutai/moshi-v01-release-66eaeaf3302bef6bd9ad7acd
在线尝试: https://moshi.chat/







 NameGPT名称生成器
NameGPT名称生成器