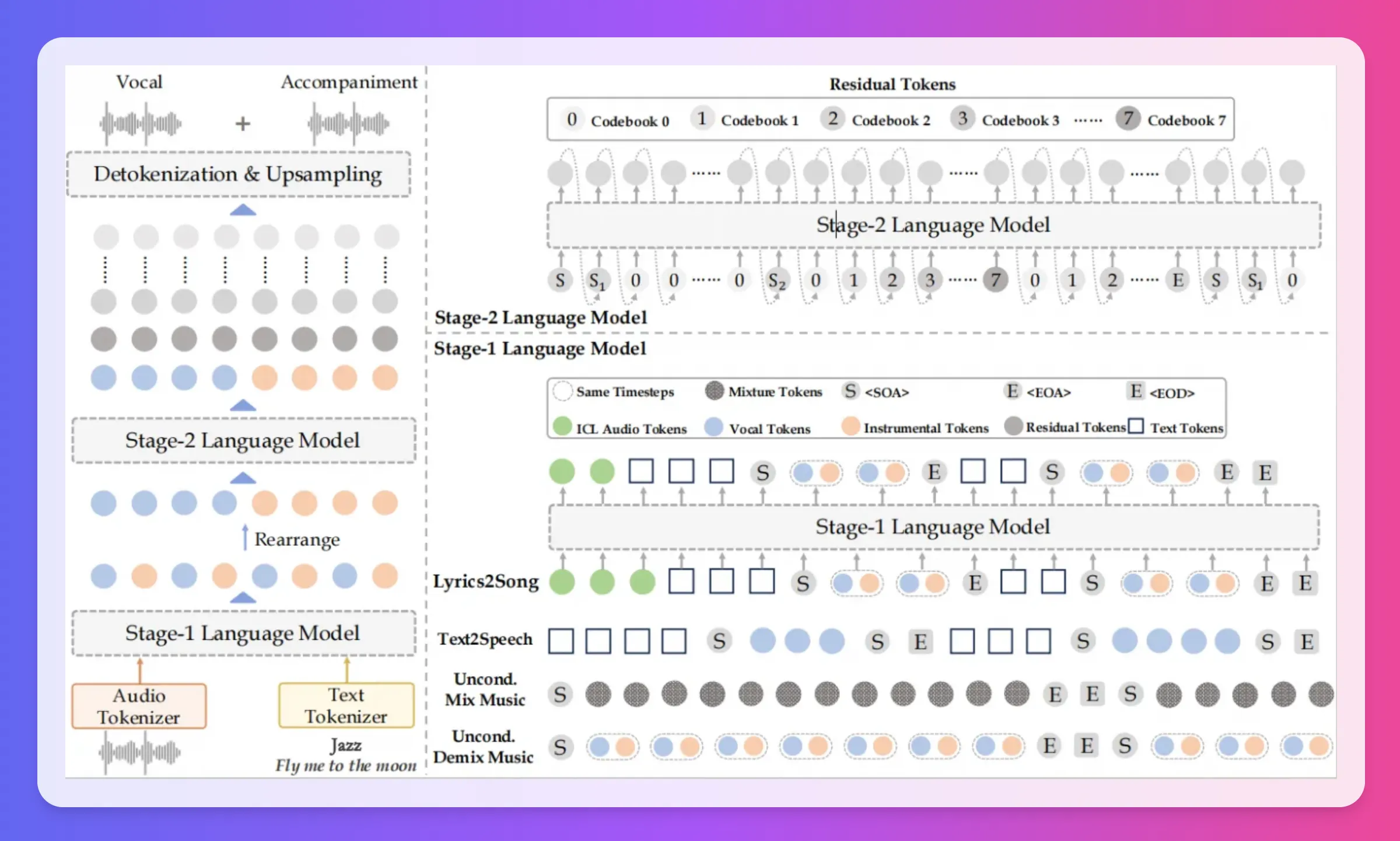
YuE是一个全新的多模态音乐开源模型,YuE具有从歌词生成高质量音乐的能力。能够生成长达5分钟的完整音乐作品,包括人声和伴奏,支持多种语言生成,如英语、中文、日语和韩语,YuE模型适用于音乐创作、歌词生成和多语言音乐制作等领域。
YuE功能特点:
多语言支持:YuE能够处理多种语言的歌词输入,生成相应的音乐作品。
高质量音乐生成:该模型不仅生成音乐的旋律,还能合成伴奏和人声。
长时间音乐创作:YuE可以生成长达5分钟的音乐,这对于许多应用场景,如短视频配乐、游戏音乐等,都是非常实用的。
开源特性:YuE允许开发者和研究者自由使用和修改。
YuE模型的另一个重要特点是其支持多种情感和风格的音乐生成。通过分析输入的歌词,YuE能够识别出所需的情感基调,并生成与之匹配的音乐风格。这种能力使得YuE在个性化音乐创作方面具有更大的灵活性和适应性。
此外,YuE还可以与其他多模态模型结合使用,例如与图像生成模型联动,创建视觉和听觉相结合的艺术作品。这种跨模态的应用拓宽了YuE的使用场景,使其不仅限于音乐生成,还可以用于多媒体艺术创作、广告制作等领域。
在技术实现方面,YuE采用了先进的深度学习算法,结合了卷积神经网络(CNN)和循环神经网络(RNN),以提高音乐生成的质量和效率。这种技术架构使得YuE能够在处理复杂的音乐结构时,保持高效的生成速度和准确性。
YuE应用场景
音乐创作:音乐制作人可以利用YuE快速生成旋律和伴奏。
影视配乐:在电影、电视剧和短视频制作中,YuE可以为不同场景生成合适的背景音乐。
游戏开发:游戏开发者可以使用YuE生成游戏中的音乐,增强游戏的沉浸感。
教育和研究:音乐教育者和研究人员可以利用YuE进行音乐创作的教学和研究。
项目地址:https://map-yue.github.io/
GitHub:https://github.com/multimodal-art-projection/YuE