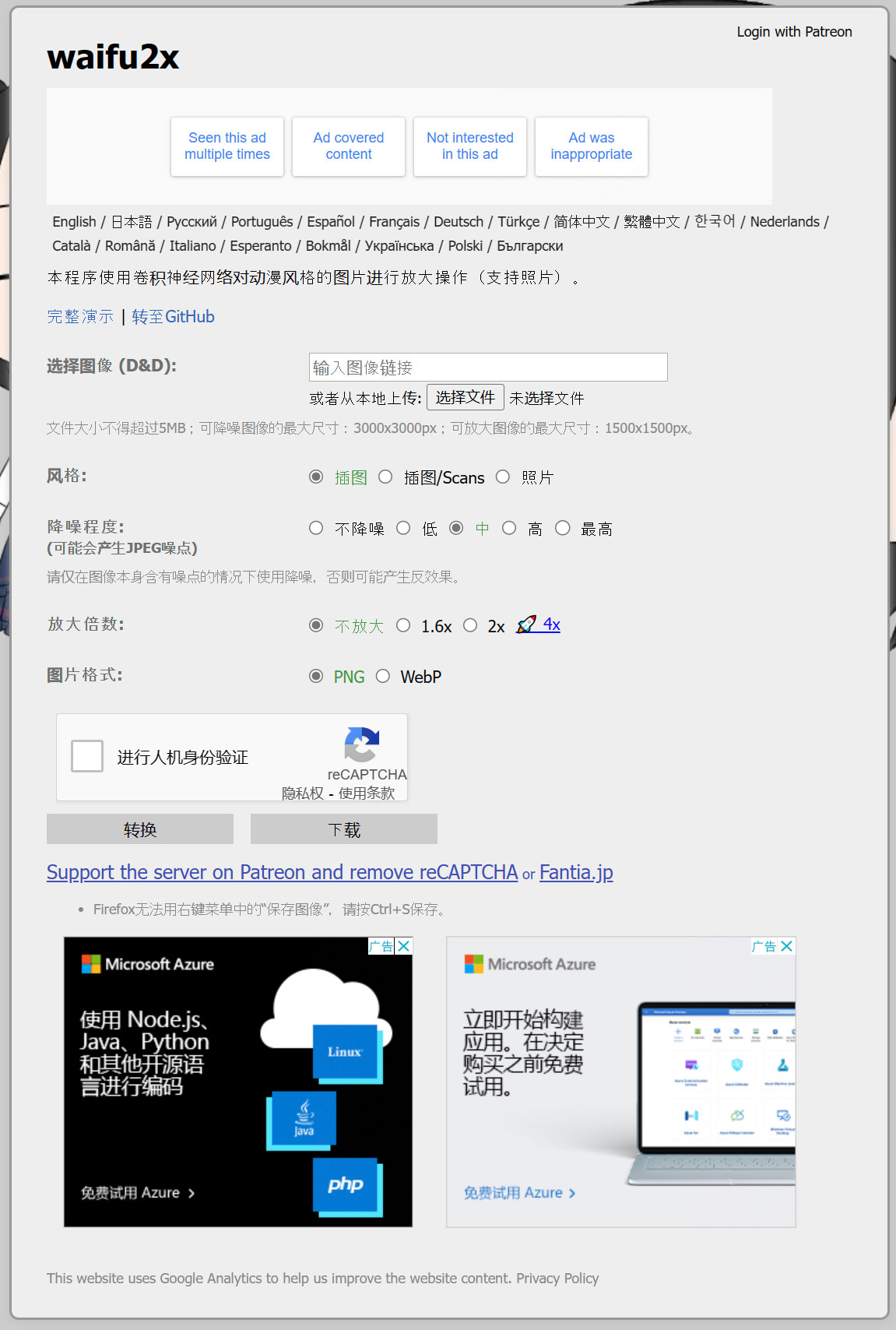
Waifu2x来自GitHub 上的一个著名的开源项目,使用深度卷积神经网络实现图片无损放大。针对二次元图片效果最佳。可选择插图或照片,放大 1~2 倍,支持降噪处理。
Waifu2x是一款强大的图像增强和质量改进工具,专为动漫风格的艺术和照片量身定制。Waifu2x能够在保留和增强视觉细节的同时升级低分辨率图像,这使Waifu2x成为艺术家、设计师以及任何处理动漫风格艺术作品或低质量图像的人的宝贵工具。
传统插入拉伸放大几乎都无法避免锯齿、线条模糊、色块、马赛克等问题。二次元图片描黑边和色块上色的特点,线条的锐利度和色块的纯净度直接影响观感。waifu2x就是针对二次元图片这个特点开发的,经过6000张高分辨率PNG图片训练而成。得益于waifu2x算法的超分辨率成像(Super-resolution)+降噪机制,可以放大图片而在大部分情况不出现插入拉伸的问题。
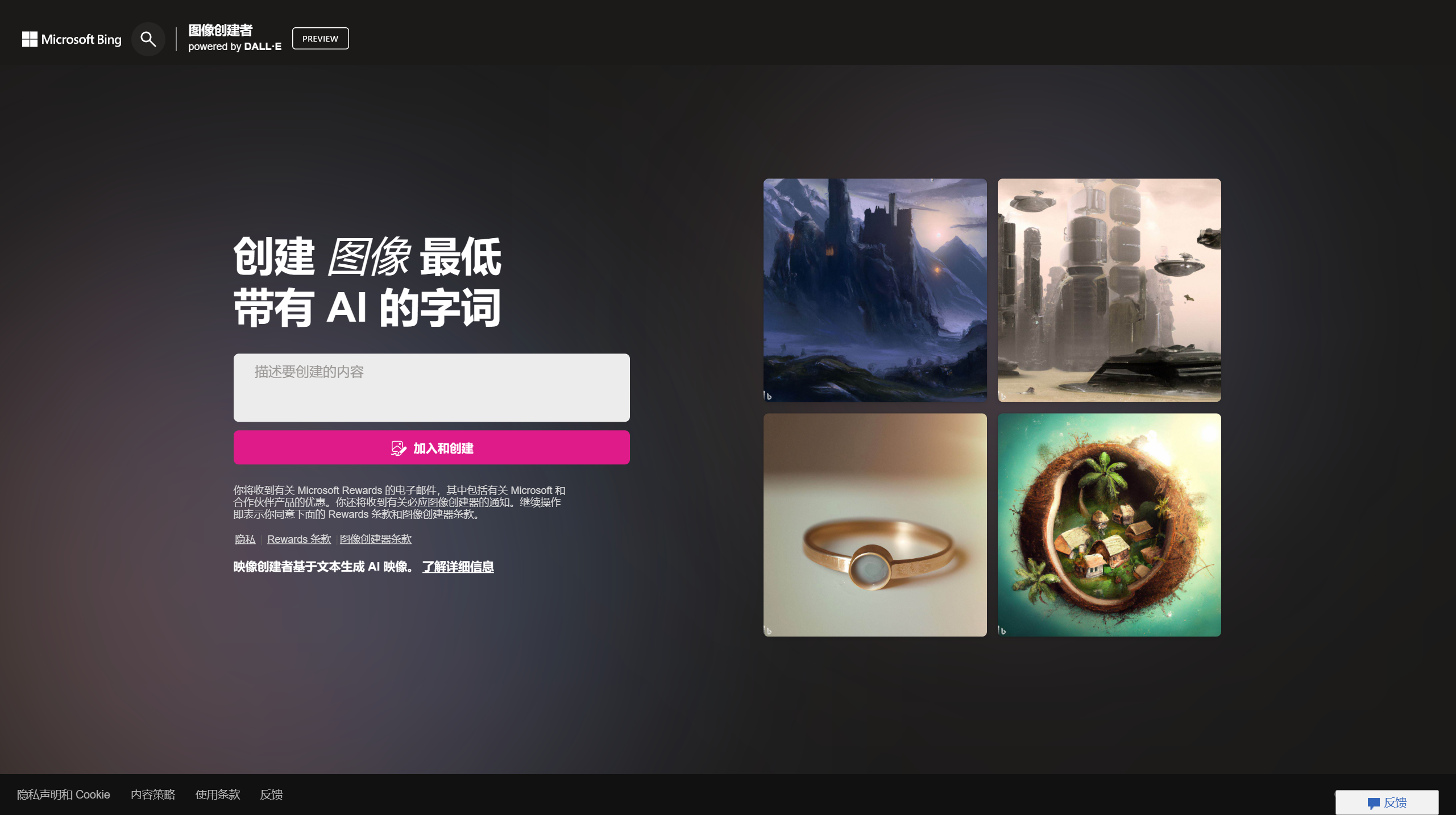
Waifu2x网页版功能特性:
上传文件:大小最大为5MB;
可进行降噪处理的图像最大为3000x3000px;
可进行放大处理的图像最大为1500x1500px;
处理风格:可选择插图或是照片风格,默认为插图选择照片风格时有彩蛋;
降噪程度:waifu2x用于消除JPEG等图像因有损压缩产生的色块和噪点,使画面看起来更干净,有低、中、高、最高四个等级,外加一个不降噪的选项,默认为中(当然降噪本质上是在削减原图信息,破坏细节,所以这个程度需要人为把握。降噪力度过强,可能连鼻子都会被抹掉);
放大倍数:waifu2x有不放大、1.6x、2x三级。
相关资讯:
waifu2x使用教程