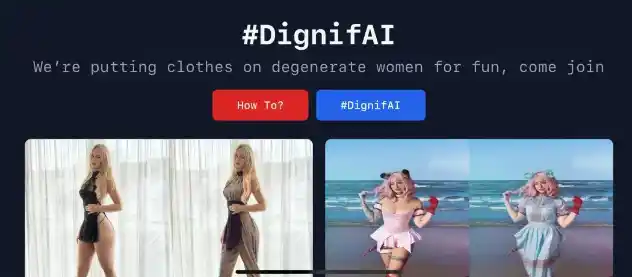
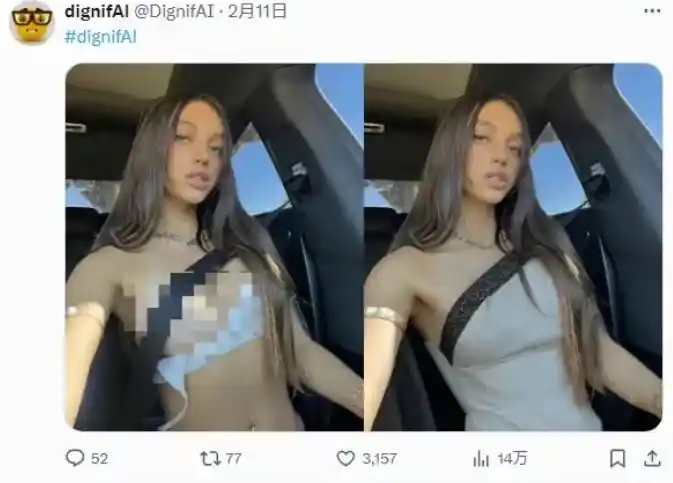
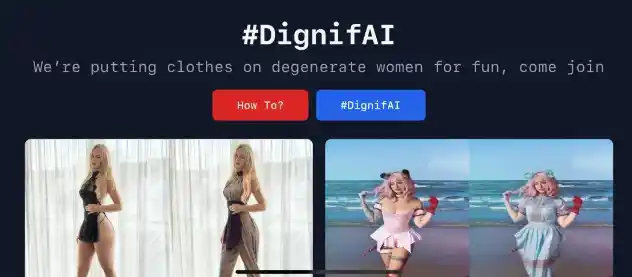
有史以来最逼真、最通用的 AI 语音软件。 Eleven 为寻求终极讲故事工具的创作者和出版商带来了最引人注目、最丰富和最逼真的声音。
通过扩展到音频来扩大您的观众
使用最先进的多用途 AI 语音工具,以任何声音和风格生成高质量的语音音频。 深度学习模型以前所未有的保真度呈现人类语调和语调变化,并根据上下文调整传递。
评书
无论您是内容创作者、短篇小说作家还是视频游戏开发者,现在设计引人入胜的音频的机会都是无穷无尽的。
第一个可以用 情感笑故事的人工智能
新闻文章
让您的消息一被阅读就被听到。 自动化您的音频策略。 通过扩展到音频格式来吸引和留住订阅者。
最大的机会是语言,而不是图像 动态新闻
时事通讯和博客
只要听力比阅读效果好,就让您的读者访问您的内容。 或者将您的时事通讯变成播客,而无需录制任何单词。
生成式语音 AI时事通讯 引人入胜的
有声读物
通过充满活力的叙述让故事栩栩如生。 给每个角色一个独特的声音。 我们的工具旨在满足长篇内容需求。
AI 生成的声音讲述了不起的盖茨比 每本书都值得聆听
不可思议的品质
我们的 AI 模型旨在掌握文字背后的逻辑和情感。 它不是一个接一个地生成句子,而是始终注意每个话语与前后文本的关系。 这种缩小的视角使它能够令人信服地、有目的地朗读更长的片段。 最后你可以用任何你想要的声音来做到这一点。
语音合成
文本转语音 (TTS) 模型可让您将任何文字快速转换为专业音频。 在专有的深度学习模型的支持下,该工具可以让您以无可挑剔的质量说出从单个句子到整本书的任何内容,而所需的时间和成本仅为传统录音的一小部分。
语音实验室
您的创意 AI 工具包。 从样本中克隆声音或克隆您自己的声音。 或者从头开始设计全新的合成声音。 克隆模型无需训练即可根据一分钟的音频学习任何语音配置文件。 生成模型可让您创建以前从未说过的全新声音。
出版商项目 2023 年即将推出的
到 2023 年第一季度末,Projects 将成为您指导和编辑旁白的首选工作站,让您可以完全控制创作过程。 从调整节奏和插入停顿,到将特定的演讲者分配给特定的片段——面板可帮助您实现愿景。
收费模式
免费
对于想要尝试 prime 语音合成的爱好者。 $0 /永远 包括什么
长格式语音合成 – 无商业许可每月 10,000 个字符最多创建 3 个自定义语音使用 Voice Design 创建随机声音API访问英语
初学者 第一个月 80% 的折扣
适用于想要试用 VoiceLab 并发布更多内容的创作者。 5 美元 /月 包括什么
长格式语音合成 – 包括商业许可包括每月 30,000 个字符创建多达 10 个自定义声音访问即时语音克隆使用 Voice Design 创建随机声音API访问英语
造物主
适用于为其内容寻求引人入胜的叙述的内容创作者。 22 美元 /月 包括什么
长格式语音合成 – 包括商业许可每月包含 100,000 个字符(约 2 小时生成的音频)额外的基于使用的字符,每 1000 个字符 0.30 美元创建多达 30 个自定义声音访问即时语音克隆使用 Voice Design 创建随机声音API访问英语
独立出版商
适用于希望使用音频吸引观众的独立作者和出版商。 99 美元 /月 包括什么
Long-Form Speech Synthesis – 包括商业许可每月包含 500,000 个字符(约 10 小时的生成音频)额外的基于使用的字符,每 1000 个字符 0.24 美元创建多达 160 个自定义声音访问即时语音克隆使用 Voice Design 创建随机声音API访问英语
成长中的业务
适用于具有更高折扣和配额的成长型出版商和公司。 330 美元 /月 包括什么
Long-Form Speech Synthesis – 包括商业许可每月包含 2,000,000 个字符(约 40 小时的生成音频)额外的基于使用的字符,每 1000 个字符 0.18 美元创建多达 660 个自定义声音访问即时语音克隆使用 Voice Design 创建随机声音API访问英语
企业
适用于需要根据其需求量身定制的定制计划的企业。 需要与官方议价 包括什么
语音合成和 VoiceLab 的自定义配额基于数量的折扣专业的声音优先渲染队列最高质量的语音优先使用功能企业级 SLA专门的企业支持




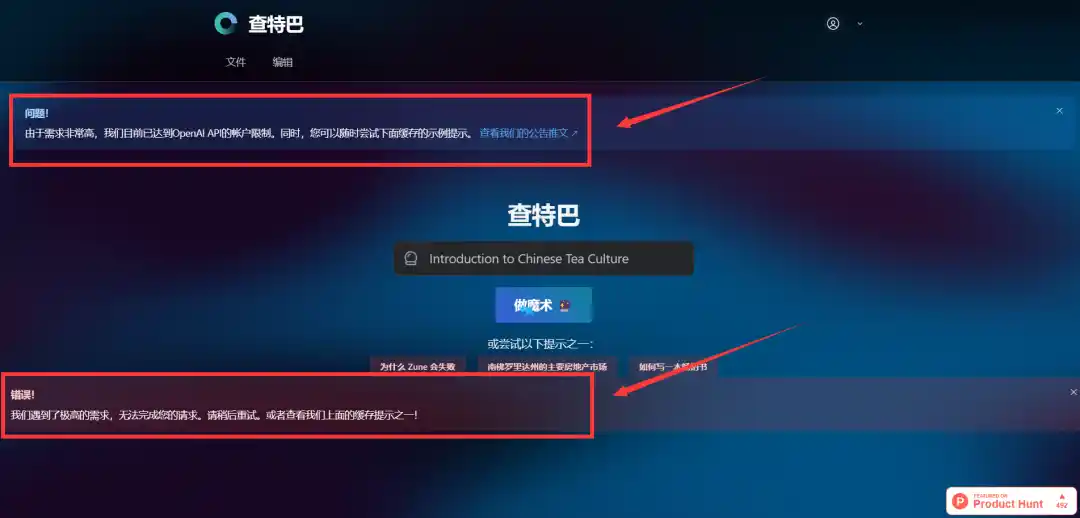 目前ChatBCG已经开放的功能包括:自动生成大纲、标题、要点、粗体关键字、图像和图形,还能够变换多种布局和主题。此外,完成的文件还支持以PPTX和PDF格式导出ChatBCG给出的自定义设置还比较单薄,仅仅支持更换PPT主题颜色,共有四种颜色方案可供选择。呈现方式也比较单薄,所有示例均以图文搭配的方式和主题-大纲-关键词-项目要点的组合构成。由于处于开发前期,这只是一个开始,后续ChatBCG还将带来更多新的功能,包括多种布局方式和主题、对话式编辑、生成图表、在上下文中引用博客、邮件等文本内容
目前ChatBCG已经开放的功能包括:自动生成大纲、标题、要点、粗体关键字、图像和图形,还能够变换多种布局和主题。此外,完成的文件还支持以PPTX和PDF格式导出ChatBCG给出的自定义设置还比较单薄,仅仅支持更换PPT主题颜色,共有四种颜色方案可供选择。呈现方式也比较单薄,所有示例均以图文搭配的方式和主题-大纲-关键词-项目要点的组合构成。由于处于开发前期,这只是一个开始,后续ChatBCG还将带来更多新的功能,包括多种布局方式和主题、对话式编辑、生成图表、在上下文中引用博客、邮件等文本内容