

Creative Fast AID官网
AI生成创意概念和想法

Creative Fast AID简介
需求人群:
为NGO或品牌生成创意概念和想法
产品特色:
基于TRIAD的最获奖广告活动进行训练
生成15个创意概念
漂亮的PDF演示文稿
Creative Fast AID官网入口网址
http://www.creativefastaid.com
小编发现Creative Fast AID网站非常受用户欢迎,请访问Creative Fast AID网址入口试用。
AI生成创意概念和想法
为NGO或品牌生成创意概念和想法
基于TRIAD的最获奖广告活动进行训练
生成15个创意概念
漂亮的PDF演示文稿
http://www.creativefastaid.com
小编发现Creative Fast AID网站非常受用户欢迎,请访问Creative Fast AID网址入口试用。

多语种实时翻译与聊天

“适用于需要进行跨语言沟通的用户,如国际商务、跨国交流、多语种社交等场景。”
在国际商务谈判中,利用Translaite进行跨语言沟通,提高效率
在多语种社交平台上,使用Translaite与来自不同国家的朋友进行交流
在旅行中,利用Translaite与当地人进行简单的交流
利用OpenAI的功能生成智能的情境感知响应
利用DeepL将信息实时翻译成多种语言
实时传输翻译好的回复给用户
https://www.translaite.com/
小编发现Translaite网站非常受用户欢迎,请访问Translaite网址入口试用。

准确的AI转录工具

Riverside适用于各种场景,包括采访记录、会议记录、语音笔记等。无论您是记者、学生、专业人士还是个人用户,Riverside都能帮助您快速而准确地转录音频和视频。
准确的AI转录
支持100+种语言
实时编辑和多人协作
高音质录音
快速而准确的转录功能
https://riverside.fm/transcription
小编发现AI Transcription by Riverside网站非常受用户欢迎,请访问AI Transcription by Riverside网址入口试用。

基于 AI 的协作式写作、头脑风暴、博客出版和协作平台

“适用于需要协同写作、头脑风暴并快速发布博客的团队和个人。”
企业内容营销团队使用 Axcent 进行协作式写作和头脑风暴,快速策划和撰写优质博客文章。
学生小组使用 Axcent 的实时协作功能进行报告和论文的团队创作。
个人博客作者通过 Axcent 快速构思、撰写和发布优质原创博文。
协作 AI 加持的写作和头脑风暴
团队和 AI 的实时聊天与协作
超快速 SEO 优化的博客出版
表单构建器
AI 上下文和历史记忆
https://axcent.io/
小编发现Axcent网站非常受用户欢迎,请访问Axcent网址入口试用。

AI图片放大增强

适用于风景、肖像、插图、动漫、室内设计等场景
将风景图片增强至高分辨率
给肖像照片添加更多细节
去除AI插图中的伪像
将AI图片增强至高分辨率
添加令人惊叹的细节
去除AI图片的伪像
将AI图片转化为真正的杰作
https://clarityai.cc
小编发现ClarityAI网站非常受用户欢迎,请访问ClarityAI网址入口试用。

Prometheus是创新的3D感知潜在扩散模型,专门用于快速生成文本到3D场景的内容。能在几秒钟内完成对象和场景级别的3D生成,同时保持高质量的输出和良好的泛化能力。核心在于基于2D先验知识来驱动高效且可泛化的3D合成过程。通过将3D场景生成表述为多视图、前馈、像素对齐的3D高斯生成过程,在潜在扩散范式内进行操作,Prometheus能有效地从文本描述中生成具有丰富细节和准确几何结构的3D场景。基于预训练的文本到图像生成模型进行微调,引入RGB-D潜在空间来解耦外观和几何信息,提升生成的保真度和几何质量。

高效的3D生成:能在几秒钟内生成复杂的3D场景,包括对象和整个场景级别,提高3D内容创作的效率。高质量输出:生成的3D场景在视觉保真度和几何质量上表现出色,能准确地反映文本描述中的细节和背景信息。良好的泛化能力:通过在大规模单视图和多视图数据集上进行训练,Prometheus能泛化到各种不同的3D对象和场景,具有与Stable Diffusion相当的泛化能力。多视图一致性:生成的3D场景在多视图下保持一致性,在大旋转或极端视角下也能保持稳定的视觉效果。文本到3D的对齐:生成的3D场景能准确地与输入的文本提示对齐,确保生成的内容符合用户的描述和期望。
两阶段训练框架第一阶段:3D高斯变分自编码器(GS-VAE)使用预训练的图像编码器(如Stable Diffusion的编码器)将RGB图像和预测的单目深度图编码到潜在空间。通过多视图Transformer整合跨视图信息,并注入相机姿态信息。将融合后的隐空间变量解码为像素对齐的3D高斯场景。像素对齐的3D高斯场景,作为场景级别的表示。第二阶段:多视图潜在扩散模型(MV-LDM)通过去噪扩散过程,联合预测多视图RGB-D潜在空间代码,条件为相机姿态和文本提示。从随机采样的高斯噪声开始,通过迭代去噪过程恢复多视图隐空间编码。多视图RGB-D潜在空间代码,用于生成最终的3D场景。RGB-D潜在空间的引入:Prometheus引入RGB-D潜在空间,将外观(RGB)和几何信息(D)解耦,提升生成的保真度和几何质量。模型能更高效地生成3D高斯,同时保持高质量的视觉效果。前馈生成策略:Prometheus采用前馈生成策略,相比传统的优化方法,减少了生成时间,提高了生成效率。通过从潜在空间中采样多视图RGB-D潜在空间代码,使用GS-VAE解码器解码为3D高斯场景,实现了快速且高质量的3D场景生成。无分类器引导(CFG):为了确保生成的3D场景与文本提示对齐,Prometheus使用无分类器引导(CFG)来引导多视图生成过程。通过调整引导强度,平衡多视图一致性和保真度,避免生成结果中的多视图不一致问题。大规模数据集训练:Prometheus在大规模单视图和多视图数据集上进行训练,确保模型具有良好的泛化能力。数据集包括多种场景类型,如对象中心、室内、室外和驾驶场景,文本提示由多模态大语言模型生成。损失函数:在训练过程中,Prometheus使用多种损失函数,包括均方误差(MSE)损失、感知损失和尺度不变深度损失,确保生成的3D场景在视觉和几何上与输入图像和深度图对齐。
项目官网:https://freemty.github.io/project-prometheusarXiv技术论文:https://arxiv.org/pdf/2412.21117
内容创作:快速生成逼真的3D场景和对象,用于VR和AR应用中的虚拟环境构建。例如,创建虚拟展览、虚拟旅游、虚拟教育场景等。实时交互:在VR和AR应用中,用户可以通过文本输入实时生成和修改3D场景,增强交互体验。场景设计:快速生成游戏中的各种场景,如城市、森林、沙漠等,提高游戏开发效率。开发者可以通过简单的文本描述生成复杂的3D环境,减少手动建模的时间和成本。概念设计:建筑师和室内设计师可以使用Prometheus快速生成建筑和室内设计的3D模型,用于初步设计和客户展示。通过文本描述,快速生成不同风格和布局的3D场景,提高设计效率。虚拟展示:生成的3D场景可以用于虚拟展示,客户可以通过VR设备沉浸式地体验设计效果,提供更直观的反馈。

自动化客户支持的网页集成工具

“企业客户服务、网页客户支持自动化、在线客户咨询”
为企业网站提供自动化客户咨询服务
使用AI聊天机器人处理常见客户问题
通过智能查询快速获取产品信息
智能查询响应
全面的产品知识库
AI驱动的聊天机器人
自定义的客户支持页面
https://productassist.in/
小编发现ProductAssist网站非常受用户欢迎,请访问ProductAssist网址入口试用。

PDF文件处理工具

个人、企业、学生等需要处理PDF文件的用户
个人用户可以使用PDF.ai插件编辑和转换PDF文件
企业用户可以使用PDF.ai插件合并和提取PDF文件内容
学生可以使用PDF.ai插件浏览和转换PDF文件格式
浏览PDF文件
编辑PDF文件
转换PDF文件格式
提取PDF文件内容
合并PDF文件
https://pdf.ai/tools/resume-ai-scanner
小编发现PDF.ai网站非常受用户欢迎,请访问PDF.ai网址入口试用。

AI写作助手,帮助您秒级提升内容质量

Wonder AI非常适合学生、作家和专业人士提升内容质量。无论您是写一篇论文、一篇博客文章还是一份营销文案,Wonder AI都能帮助您改善内容。
重写 – 利用AI技术使您的内容更加简明扼要
微调 – 发挥GPT的能力,进行细微调整而不失内容的本质
拼写检查 – 使用AI和ChatGPT学习算法,纠正内容中的语法和拼写错误
摘要 – 利用AI将您的内容的核心精髓浓缩成简明而精确的摘要
解释 – 利用GPT的能力,提供对内容的清晰详细的理解
翻译 – 借助AI,准确地将您的文本从一种语言翻译成另一种语言
https://chrome.google.com/webstore/detail/wonder-ai-your-gpt-writin/kipleafooljlggggpiinilijkokogbkb?hl=en
小编发现Wonder AI – Your GPT writing assistant网站非常受用户欢迎,请访问Wonder AI – Your GPT writing assistant网址入口试用。

MinMo是阿里巴巴通义实验室FunAudioLLM团队推出的多模态大模型,专注于实现无缝语音交互。MinMo拥有约80亿参数,基于多阶段训练,在140万小时多样化语音数据和广泛语音任务上进行学习。MinMo支持根据用户指令控制生成音频的情感、方言和说话风格,及模仿特定音色,生成效率超过90%。MinMo支持全双工语音交互,语音到文本延迟约为100毫秒,全双工延迟理论上约为600毫秒,实际约为800毫秒,可实现用户与系统之间的同时双向通信,使多轮对话更加流畅。
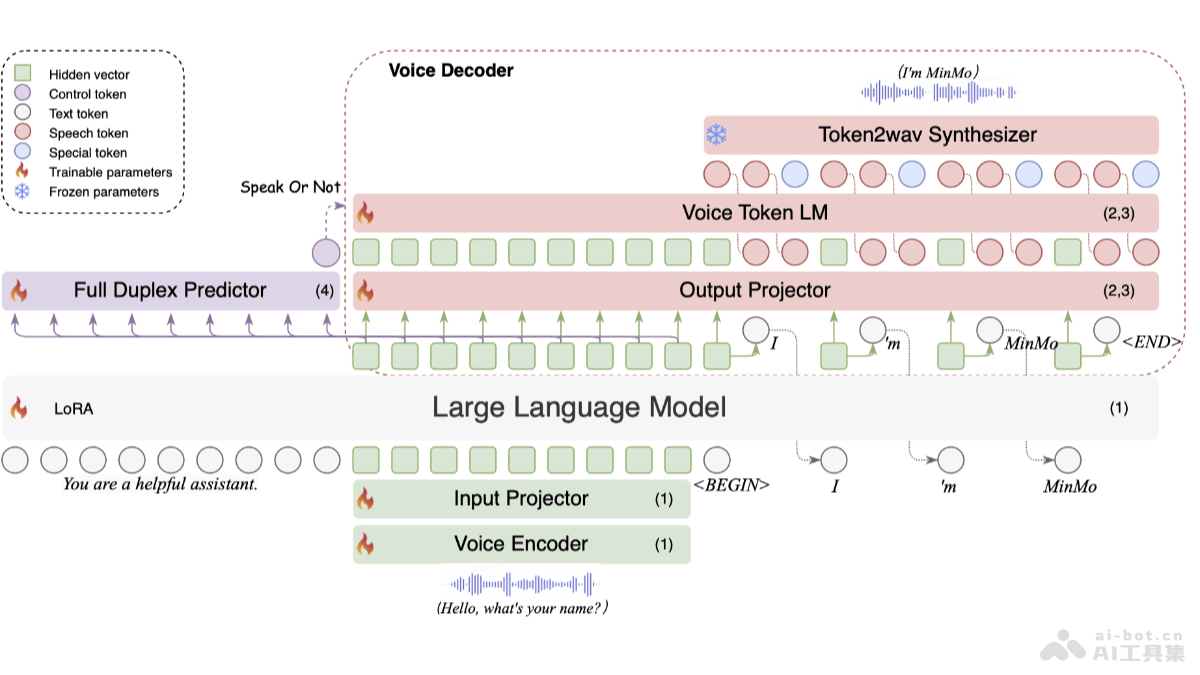
实时语音对话:能实时、自然、流畅地与用户进行语音对话,理解用户的语音指令并生成相应的语音回应。多语言支持:支持多语言语音识别和翻译,在多种语言环境下与用户顺畅沟通。情感表达:根据用户指令生成带有特定情感(如快乐、悲伤、惊讶等)的语音。方言和说话风格:支持生成特定方言(如四川话、粤语等)和特定说话风格(如快速、慢速等)的语音。音色模仿:模仿特定音色,让语音交互更具个性化和表现力。全双工交互:支持用户和系统同时说话和聆听,实现更自然、高效的多轮对话,语音到文本延迟约为100毫秒,全双工延迟理论上约为600毫秒,实际约为800毫秒。
多模态融合架构:语音编码器:基于预训练的SenseVoice-large编码器模块,提供强大的语音理解能力,支持多语言语音识别、情感识别和音频事件检测。输入投影器:由两层Transformer和一层CNN组成,用在维度对齐和降采样。大型语言模型:用预训练的Qwen2.5-7B-instruct模型,因其在多个基准测试中表现出色。输出投影器:单层线性模块,用在维度对齐。语音标记语言模型:用预训练的CosyVoice 2 LM模块,自回归生成语音标记。Token2wav合成器:将语音标记转换为mel频谱图,再转换为波形,支持实时音频合成。全双工预测器:单层Transformer和线性softmax输出层,用在实时预测是否继续系统响应或暂停处理用户输入。多阶段训练策略:语音到文本对齐:基于大量语音数据和对应的文本标注,训练模型学习语音和文本之间的映射关系,让模型准确地将语音转换为文本,为后续的文本理解和生成打下基础。文本到语音对齐:让模型学习如何将文本转换为语音,生成自然流畅的语音表达,保持文本的语义信息和情感色彩。语音到语音对齐:进一步提升模型对语音的理解和生成能力,让模型直接在语音层面进行交互,更好地处理语音的韵律、语调等特征。双工交互对齐:模拟真实的全双工交互场景,训练模型在同时接收和发送语音信号的情况下,准确地进行语音识别和生成,优化模型在复杂交互环境下的性能。
项目官网:https://funaudiollm.github.io/minmo/arXiv技术论文:https://arxiv.org/pdf/2501.06282
智能客服:提供24*7多语言语音支持,实时互动解答客户问题,基于情感识别提供个性化服务,支持全双工对话提高效率。智能助手:控制智能家居设备,管理日程,查询信息,推荐个性化内容,提升生活便利性和信息获取效率。教育领域:辅助语言学习,互动教学提高参与度,根据学习进度提供个性化计划,情感支持鼓励学生学习。医疗健康:远程医疗咨询,健康监测提醒,康复训练指导,情感支持疏导,提升医疗服务的可及性和患者体验。智能驾驶:语音控制车辆系统,提供实时交通信息,紧急情况指导,全双工对话提高驾驶安全性和便利性。