

Speechless官网
无限语言沟通

Speechless简介
需求人群:
“用于音频转录和翻译,跨语言沟通”
产品特色:
无缝的音频转录
实时翻译
支持 WhatsApp、语音备忘录等应用
Speechless官网入口网址
https://apps.apple.com/us/app/id6456413273
小编发现Speechless网站非常受用户欢迎,请访问Speechless网址入口试用。
无限语言沟通
“用于音频转录和翻译,跨语言沟通”
无缝的音频转录
实时翻译
支持 WhatsApp、语音备忘录等应用
https://apps.apple.com/us/app/id6456413273
小编发现Speechless网站非常受用户欢迎,请访问Speechless网址入口试用。
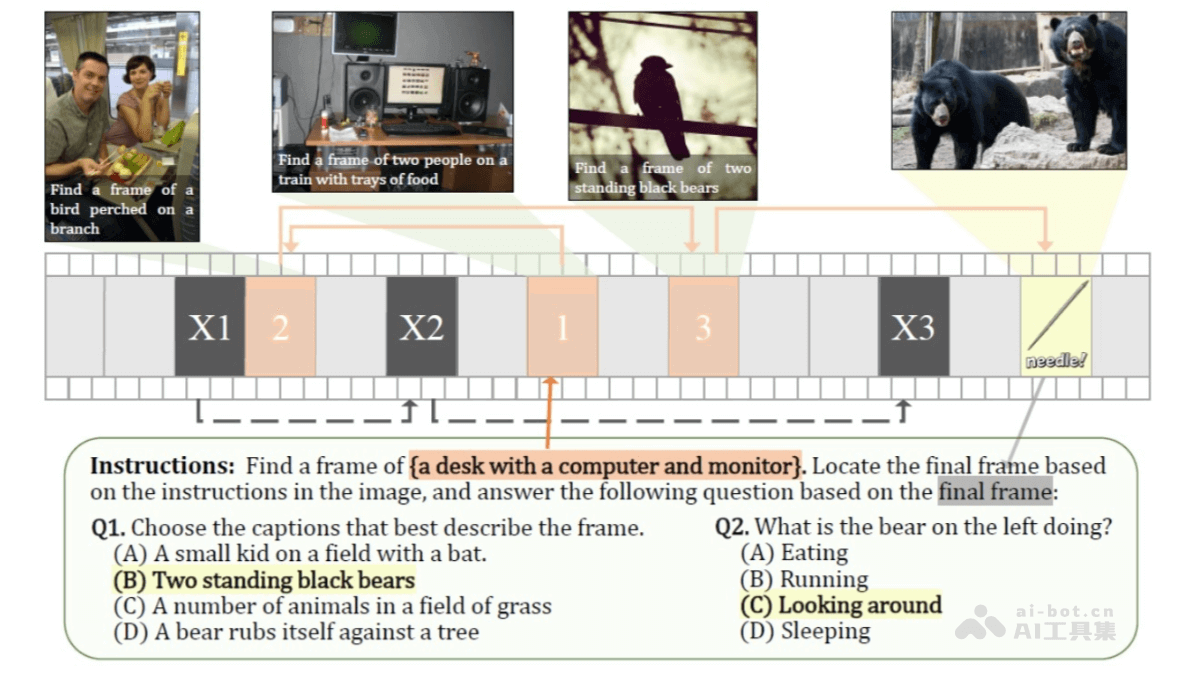
VideoChat-Flash 是上海人工智能实验室和南京大学等机构联合开发的针对长视频建模的多模态大语言模型(MLLM),模型通过分层压缩技术(HiCo)高效处理长视频,显著减少计算量,同时保留关键信息。采用多阶段从短到长的学习方案,结合真实世界长视频数据集 LongVid,进一步提升对长视频的理解能力。
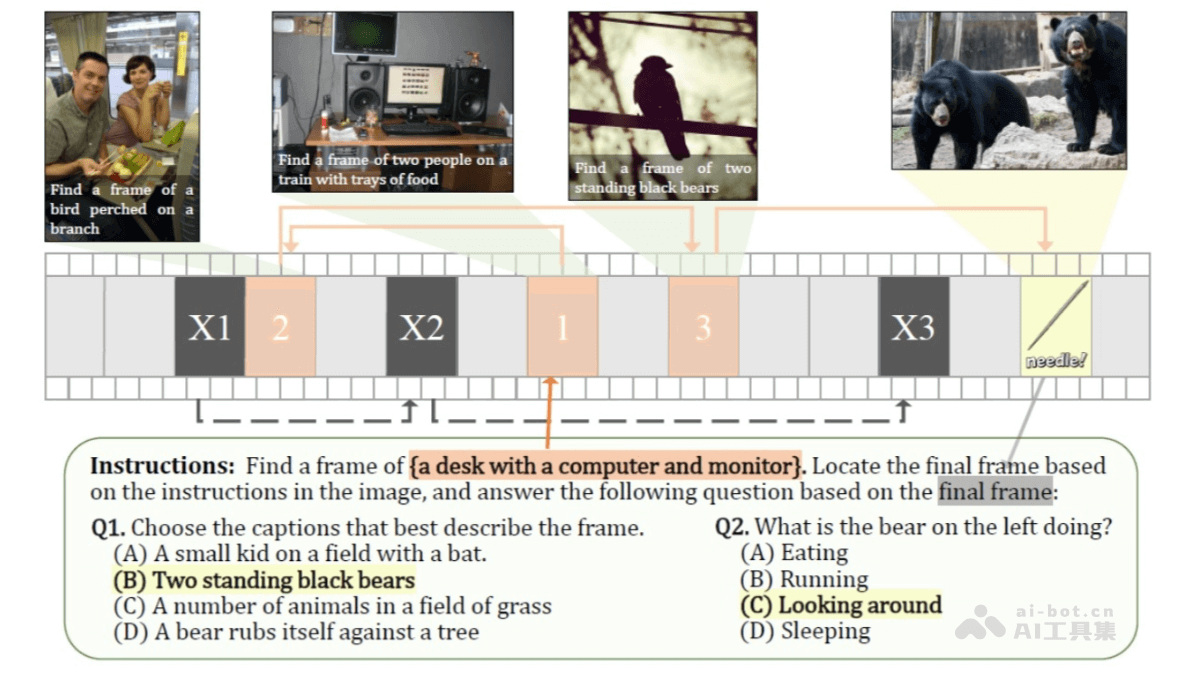
长视频理解能力:VideoChat-Flash 通过分层压缩技术(HiCo)有效处理长视频,能处理长达数小时的视频内容。在“针在干草堆中”(NIAH)任务中,首次在开源模型中实现了 10,000 帧(约 3 小时视频)的 99.1% 准确率。高效模型架构:模型通过将每个视频帧编码为仅 16 个 token,显著降低了计算量,推理速度比前代模型快 5-10 倍。多阶段从短到长的学习方案,结合真实世界的长视频数据集 LongVid,进一步提升了模型的性能。强大的视频理解能力:VideoChat-Flash 在多个长视频和短视频基准测试中均表现出色,超越了其他开源 MLLM 模型,甚至在某些任务中超过了规模更大的模型。多跳上下文理解:VideoChat-Flash 支持多跳 NIAH 任务,能追踪长视频中的多个关联图像序列,进一步提升了对复杂上下文的理解能力。
分层压缩技术(HiCo):HiCo 是 VideoChat-Flash 的核心创新之一,旨在高效处理长视频中的冗余视觉信息。片段级压缩:将长视频分割为较短的片段,对每个片段进行独立编码。视频级压缩:在片段编码的基础上,进一步压缩整个视频的上下文信息,减少需要处理的标记数量。语义关联优化:结合用户查询的语义信息,进一步减少不必要的视频标记,从而降低计算量。多阶段学习方案:VideoChat-Flash 采用从短视频到长视频的多阶段学习方案,逐步提升模型对长上下文的理解能力。初始阶段:使用短视频及其注释进行监督微调,建立模型的基础理解能力。扩展阶段:逐步引入长视频数据,训练模型处理更复杂的上下文。混合语料训练:最终在包含短视频和长视频的混合语料上进行训练,以实现对不同长度视频的全面理解。真实世界长视频数据集 LongVid:为了支持模型训练,研究团队构建了 LongVid 数据集,包含 30 万小时的真实世界长视频和 2 亿字的注释。该数据集为模型提供了丰富的训练素材,使其能够更好地适应长视频理解任务。模型架构:VideoChat-Flash 的架构包括三个主要部分:视觉编码器、视觉-语言连接器和大语言模型(LLM)。通过这种分层架构,模型能高效地将视频内容编码为紧凑的标记序列,通过 LLM 进行长上下文建模。
GitHub仓库:https://github.com/OpenGVLab/VideoChat-FlasharXiv技术论文:https://arxiv.org/pdf/2501.00574
视频字幕生成与翻译:模型能生成详细且准确的视频字幕,适用于多语言翻译和无障碍字幕生成,帮助观众更好地理解视频内容。视频问答与交互:VideoChat-Flash 支持基于视频内容的自然语言问答,用户可以通过提问获取视频中的关键信息,例如电影剧情解析、纪录片中的知识点等。具身AI与机器人学习:在具身AI领域,VideoChat-Flash 可以通过长时间的自我视角视频帮助机器人学习复杂的任务,例如制作咖啡等,通过分析视频中的关键事件来指导机器人完成任务。体育视频分析与集锦生成:模型能分析体育比赛视频,提取关键事件并生成集锦,帮助观众快速了解比赛的精彩瞬间。监控视频分析:VideoChat-Flash 可以处理长时间的监控视频,识别和追踪关键事件,提高监控系统的效率和准确性。

Kommunicate提供基于生成式AI的聊天机器人,可实现定制化的客户交流

[“可将聊天机器人部署在网站、移动应用或任何通信渠道上,帮助客户快速解决问题”,”可与公司知识库或常见问题集成,保证客户获得最新的产品信息”]
训练聊天机器人回答常见问题
将聊天机器人集成到在线购物网站上回答购物相关询问
快速创建聊天机器人在社交软件上回答用户问题
可根据用户提供的文档、PDF、文本或网站页面 Scraper 来快速创建聊天机器人
可与 Zendesk、Salesforce 或任何知识库进行 API 集成
基于生成式 AI 提供更准确和总结式的答复,从而带来卓越的客户体验
https://www.kommunicate.io/product/generative-ai
小编发现Kommunicate网站非常受用户欢迎,请访问Kommunicate网址入口试用。

销售、营销和RevOps的AI助手

适用于销售、营销和RevOps团队的AI全能解决方案
AI文本生成:11倍速写电子邮件、博客帖子、社交媒体帖子
AI图像生成:将文本转换为图像,或通过图像创建图像
AI聊天:基本任务快速结果,高质量结果
AI音频工具:创建、转录和转换音频文件
HubSpot集成
https://aissistify.com/
小编发现AIssistify网站非常受用户欢迎,请访问AIssistify网址入口试用。

Avatar AI™是一款基于人工智能技术的头像生成工具,可以生成逼真的人物头像,满足不同用户的需求。
网站服务:AI头像生成,图像生成,人工智能,头像生成,照片编辑,图像AI,AI头像生成,图像生成,人工智能,头像生成,照片编辑。
![]()
Generate photorealistic images of people with AI。 Generate 120+ different styles of avatars based on the original Avatar AI™ that started the AI avatars tr。。。
Avatar AI™是一款基于人工智能技术的头像生成工具,可以生成逼真的人物头像。它提供了120多种不同风格的头像,只需1080秒即可完成生成。除了头像生成功能,Avatar AI™还提供了AI摄影师功能,可以训练AI模型并使用AI摄影师拍摄真实的照片。这些照片看起来非常真实,但实际上都是100%由人工智能生成的。
1. 生成逼真的人物头像:Avatar AI™可以根据用户提供的信息生成逼真的人物头像,包括不同种族、性别和风格。2. 多样化的风格选择:用户可以选择120多种不同风格的头像,满足不同用户的需求。3. AI摄影师功能:用户可以使用AI摄影师拍摄真实的照片,无需亲自出门或雇佣摄影师。4. 节省时间和成本:使用Avatar AI™可以帮助内容创作者节省时间和成本,无需进行实地拍摄或雇佣昂贵的摄影师。
1. 生成无限数量的头像:Avatar AI™可以根据用户的需求生成无限数量的头像,每个头像都具有独特的风格和特点。2. 真实逼真的效果:生成的头像看起来非常逼真,几乎无法与真实照片区分。3. 简单易用:用户只需提供一些基本信息,即可轻松生成头像,无需任何专业技能。4. 快速响应:使用Avatar AI™可以快速生成头像,节省用户的时间。
1. 社交媒体头像:用户可以使用Avatar AI™生成逼真的社交媒体头像,展示自己的个性和风格。2. 营销推广:企业可以使用Avatar AI™生成逼真的人物头像,用于营销推广活动,吸引用户的注意力。3. 虚拟形象创作:创作者可以使用Avatar AI™生成虚拟形象,用于漫画、游戏等创作领域。
1. 创建AI角色:用户可以先创建自己的AI角色,提供一些基本信息,生成一个独特的AI角色。2. 拍摄照片:用户可以使用AI角色进行拍摄,选择不同的姿势、场景和风格,生成逼真的照片。3. 复制照片:用户还可以使用已有的照片进行复制,生成与之相似的头像。4. 升级服务:用户可以选择升级到高级版,获得更多的照片生成次数和更快的响应速度。
1. 头像生成的时间是多久?生成一个头像需要1080秒,即18分钟。2. 头像生成的质量如何?生成的头像非常逼真,几乎无法与真实照片区分。3. 是否可以自定义头像的风格?是的,Avatar AI™提供了120多种不同风格的头像供用户选择。4. 是否可以使用已有的照片进行复制?是的,用户可以使用已有的照片进行复制,生成与之相似的头像。5. 是否可以升级到高级版?是的,用户可以选择升级到高级版,获得更多的照片生成次数和更快的响应速度。
https://avatarai.me
AI聚合大数据显示,Avatar Al官网非常受用户欢迎,请访问Avatar Al网址入口(https://avatarai.me)试用。

智能回答复杂问题,写邮件,阅读文章,智能搜索,无处不在

适用于各种场景,包括办公、学习、研究等
回答复杂问题
写邮件
阅读文章
智能搜索
https://chrome.google.com/webstore/detail/monica-your-ai-copilot-po/ofpnmcalabcbjgholdjcjblkibolbppb?hl=en-US
小编发现Monica – Your AI Copilot powered by GPT-4网站非常受用户欢迎,请访问Monica – Your AI Copilot powered by GPT-4网址入口试用。

每个学生的个人AI导师

“Inkey适用于所有需要写作、完成作业、构建简历等的学生,尤其是那些需要提高写作能力的学生。”
生成当前的、由AI制作的教育材料
提供20多种不同的AI工具,用于优化学生的写作
帮助学生写作、完成作业、构建简历等
https://www.inkey.ai/
小编发现Inkey网站非常受用户欢迎,请访问Inkey网址入口试用。
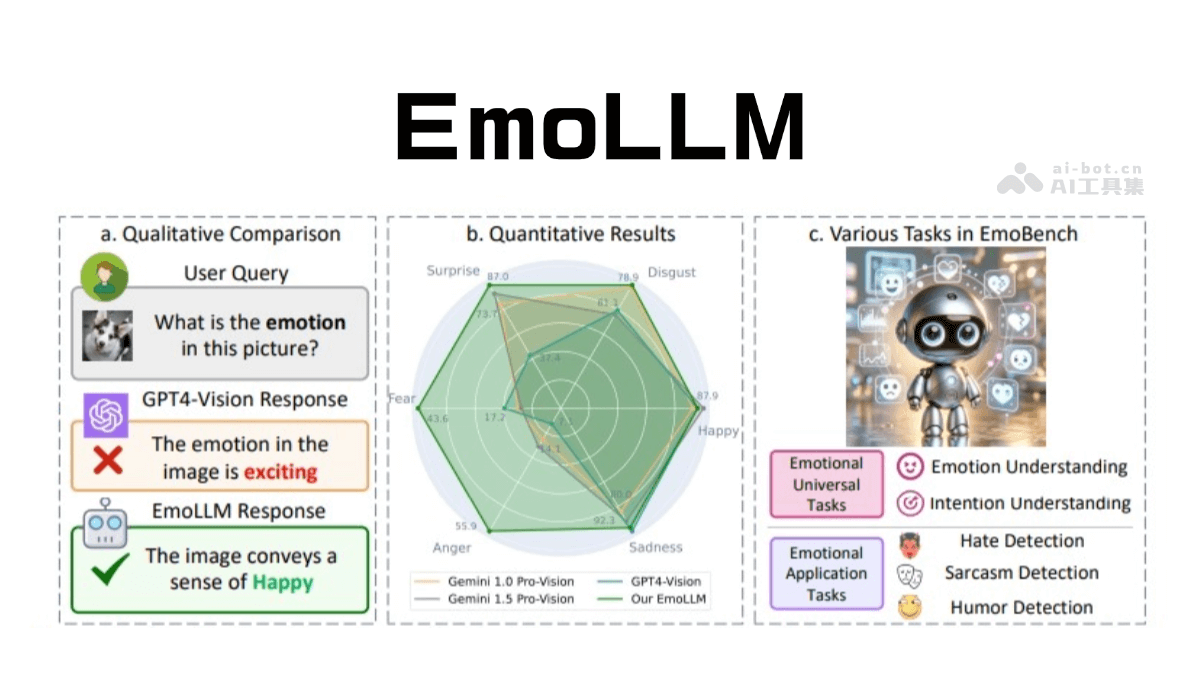
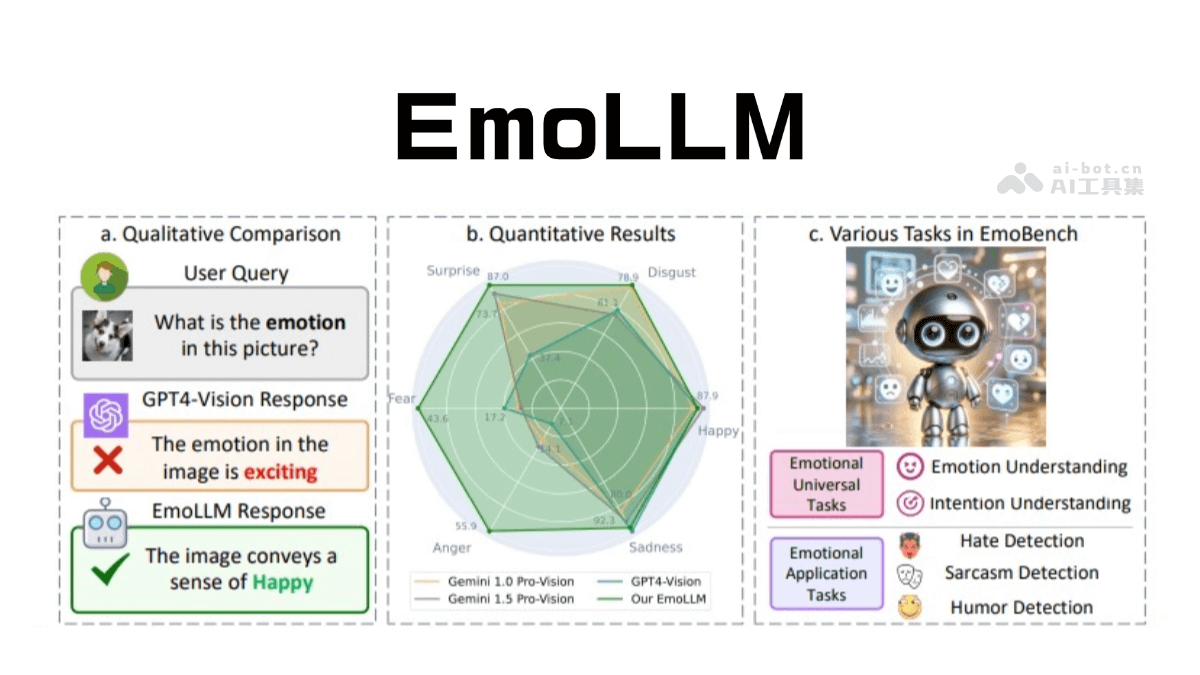
EmoLLM 是专注于心理健康支持的大型语言模型,通过多模态情感理解为用户提供情绪辅导和心理支持。结合了文本、图像、视频等多种数据形式,基于先进的多视角视觉投影技术,从不同角度捕捉情感线索,更全面地理解用户的情绪状态。EmoLLM 基于多种开源大语言模型进行指令微调,支持情绪识别、意图理解、幽默检测和仇恨检测等情感任务。
理解用户:通过对话交互,识别用户的情绪状态和心理需求。情感支持:提供情感支持,帮助用户缓解压力和焦虑。心理辅导:结合认知行为疗法等方法,引导用户改善情绪管理和应对策略。角色扮演:根据不同用户的需求,提供多种角色(如心理咨询师、温柔御姐、爹系男友等)的对话体验。个性化辅导:根据用户的反馈和进展,提供定制化的心理辅导方案。心理健康评估:使用科学工具评估用户的心理状态,诊断可能存在的心理问题。教育和预防:提供心理健康知识,帮助用户了解如何预防心理问题。多轮对话支持:通过多轮对话数据集,提供持续的心理辅导和支持。社会支持系统:考虑家庭、工作、社区和文化背景对心理健康的影响,提供社会支持系统的指导。
多视角视觉投影(Multi-perspective Visual Projection):EmoLLM 通过多视角视觉投影技术,从多个角度捕捉视觉数据中的情感线索。分析单个视角下的情感信息,通过构建基于图的表示来捕捉对象特征之间的关系。通过联合挖掘内容信息和关系信息,模型能提取出更适合情感任务的特征。情感引导提示(EmoPrompt):EmoPrompt 是用于指导多模态大型语言模型(MLLMs)正确推理情感的技术。通过引入特定任务的示例,结合 GPT-4V 的能力生成准确的推理链(Chain-of-Thought, CoT),确保模型在情感理解上的准确性。多模态编码:EmoLLM 集成了多种模态编码器,以处理文本、图像和音频等多种输入。例如,使用 CLIP-VIT-L/14 模型处理视觉信息,WHISPER-BASE 模型处理音频信号,以及基于 LLaMA2-7B 的文本编码器处理文本数据。指令微调:EmoLLM 基于先进的指令微调技术,如 QLORA 和全量微调,对原始语言模型进行精细化调整,能更好地适应心理健康领域的复杂情感语境。
GitHub仓库:https://github.com/yan9qu/EmoLLMarXiv技术论文:https://arxiv.org/pdf/2406.16442
心理健康辅导:为用户提供情绪支持和建议。情感分析:用于社交媒体情感监测、心理健康监测等。多模态情感任务:如图像和视频中的情感识别。

所有语言:文字、语音或输入以翻译并打破语言障碍

旅行、学习、商务、医疗
实时文本翻译
图片翻译
文本转语音
切换语言
免费翻译
收藏翻译
https://play.google.com/store/apps/details
小编发现Translator网站非常受用户欢迎,请访问Translator网址入口试用。

构建应用内AI聊天机器人和AI驱动的文本区域

“可以用来在Web应用中快速实现AI助手和AI驱动的文本编辑”
用作增强版的
结合使用应用内Copilot
useMakeCopilotReadable传递应用状态
CopilotTextarea: AI辅助的文本生成和编辑
Copilot Chatbot: 应用内Copilot,可以查看应用的状态
useMakeCopilotReadable: 向Copilot提供状态信息
useMakeCopilotActionable: 允许Copilot代表用户执行操作
https://github.com/CopilotKit/CopilotKit
小编发现CopilotKit网站非常受用户欢迎,请访问CopilotKit网址入口试用。