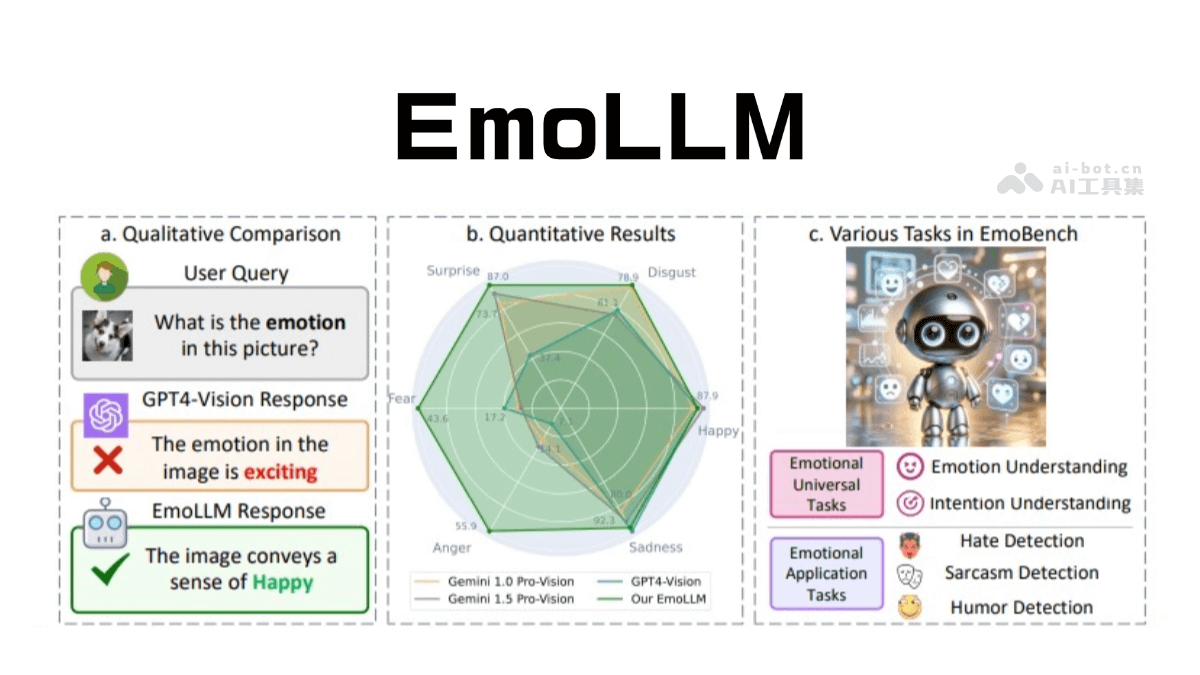
OmniManip是什么
OmniManip 是北京大学与智元机器人联合实验室开发的通用机器人操作框架,通过结合视觉语言模型(VLM)的高层次推理能力和精确的三维操作能力,实现机器人在非结构化环境中的通用操作。框架的核心在于以对象为中心的交互基元表示法,通过将任务分解为多个结构化阶段,基于 VLM 提供的常识推理能力,将自然语言指令转化为可执行的三维空间约束。

OmniManip的主要功能
零样本泛化能力:OmniManip 能处理多样化的开放词汇指令和物体,无需训练即可在多种机器人操作任务中实现强泛化能力。跨机器人形态能力:OmniManip 是种硬件无关的方法,可以轻松部署在不同类型的机器人平台上,例如双臂人形机器人。大规模仿真数据生成:OmniManip 的设计使其能自动化生成大规模的机器人操作仿真数据,为未来的研究提供了强大的数据支持。
OmniManip的技术原理
以对象为中心的交互基元表示法:OmniManip 提出了一种以对象为中心的表示方法,通过对象的功能性空间(canonical space)定义交互基元(如交互点和方向),将 VLM 的输出转化为可执行的三维空间约束。这些交互基元在对象的标准空间中定义,能在不同场景中保持一致,实现更通用和可复用的操作策略。双闭环系统设计:OmniManip 采用双闭环系统,分别用于高级规划和低级执行:闭环规划:通过交互渲染和交互原语重采样,OmniManip 实现了 VLM 的闭环推理。这一机制可以检测并纠正 VLM 推理中的错误(如幻觉问题),确保规划结果的准确性。闭环执行:在执行阶段,OmniManip 使用 6D 姿态跟踪器实时更新物体的位姿,并将其转换为机械臂末端执行器的操作轨迹,从而实现鲁棒的实时控制。任务分解与空间约束:OmniManip 将复杂任务分解为多个阶段,每个阶段通过交互基元定义空间约束。例如,在“将茶倒入杯中”的任务中,系统会分解为“抓取茶壶”和“倾倒茶水”两个阶段,并为每个阶段生成相应的交互点和方向。
OmniManip的项目地址
项目官网:https://omnimanip.github.io/GitHub仓库:https://github.com/pmj110119/OmniManiparXiv技术论文:https://arxiv.org/pdf/2501.03841
OmniManip的应用场景
日常生活中的物品操作:如倒茶、插花、整理桌面等。工业自动化:通过精确的三维操作能力,实现复杂任务的自动化。服务机器人:在非结构化环境中执行任务,如家庭服务或医疗辅助。