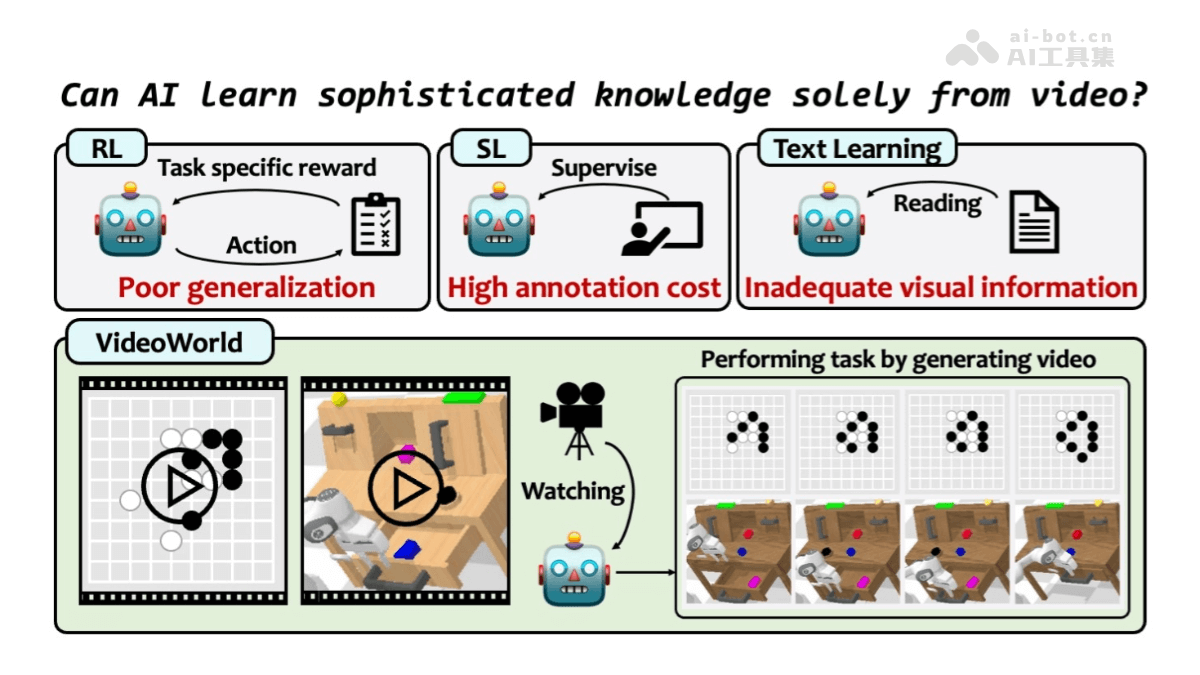
Roop-Unleashed是什么
Roop-Unleashed 是基于 Roop 的开源项目,专注于深度伪造(Deepfake)技术的实现与优化。用户无需进行复杂的训练过程,可快速实现图像和视频中的面部替换。通过浏览器图形界面(GUI)提供简单易用的操作体验,支持跨平台运行,适用于 Windows、Linux 和 macOS 系统。主要功能包括按性别、检测到的第一个面部等多种换脸模式,支持批量处理图像和视频,提供面部遮挡掩码、面部修复与增强功能,实时预览和虚拟摄像头功能,方便用户实时查看换脸效果。
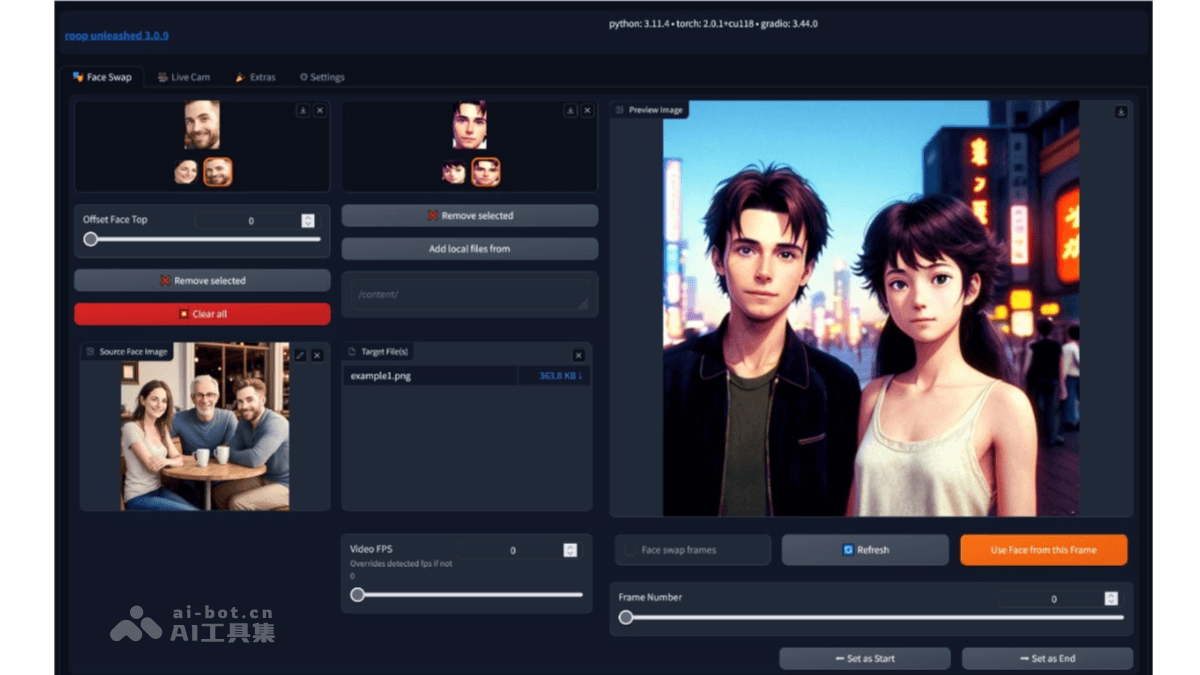
Roop-Unleashed的主要功能
多模式换脸:支持按性别、检测到的第一个面部、随机面部等多种换脸模式,满足不同场景需求。批量处理:可以批量处理图像和视频,提高工作效率。面部遮挡掩码:支持通过文本提示或自动方式对面部遮挡进行掩码处理,增强换脸效果的自然度。面部修复与增强:提供面部修复和增强功能,改善换脸后的视觉效果。实时预览与虚拟摄像头:支持从不同视频帧预览换脸效果,可通过虚拟摄像头实时生成换脸视频,方便直播或实时应用。视频剪切与设置保存:支持视频剪切功能,用户可以保存设置以便下次快速使用。多语言支持:提供多种语言界面,方便不同语言背景的用户使用。GPU 加速:支持 NVIDIA GPU 加速,提升处理速度,尤其适合处理高清视频。
Roop-Unleashed的技术原理
人脸检测与对齐:Roop-Unleashed 使用深度学习模型检测图像或视频中的人脸,通过关键点定位技术将源人脸与目标人脸对齐,确保替换的自然性。生成对抗网络(GAN):GAN 是 Roop-Unleashed 的核心技术之一。生成器负责生成逼真的替换人脸,判别器则尝试区分生成的人脸与真实人脸。通过两者的对抗训练,生成器能生成高度逼真的换脸效果。自动编码器:自动编码器用于将人脸图像编码为低维特征表示,通过解码器重建图像。能有效提取和保留源人脸的关键特征,同时将其适配到目标人脸的结构中。图像融合与优化:Roop-Unleashed 通过智能算法将生成的人脸无缝融合到原始图像或视频中,同时支持面部增强和修复功能,进一步提升换脸效果的自然度。
Roop-Unleashed的项目地址
GitHub仓库:https://github.com/C0untFloyd/roop-unleashed
Roop-Unleashed的应用场景
社交媒体内容创作:Roop-Unleashed 能帮助创作者高效制作有趣、个性化的短视频和图像内容。虚拟会议与直播:工具支持实时直播换脸功能,用户可以通过虚拟摄像头在直播或虚拟会议中实时替换面部,为观众带来全新的视觉体验,增加互动性和趣味性。影视后期制作:在影视行业,Roop-Unleashed 可用于快速替换演员的面部,节省重拍成本,提高制作效率。能精准匹配人脸特征,确保换脸效果自然逼真。个人娱乐与创作:对于个人用户,Roop-Unleashed 是娱乐性的工具。用户可以将自己的脸替换到各种有趣的情境中,生成个性化的表情包或创意视频,为生活增添乐趣。VR 内容创作:Roop-Unleashed 支持 VR 视频换脸,为 VR 爱好者提供了全新的体验方式,进一步拓展了其在沉浸式内容创作中的应用。