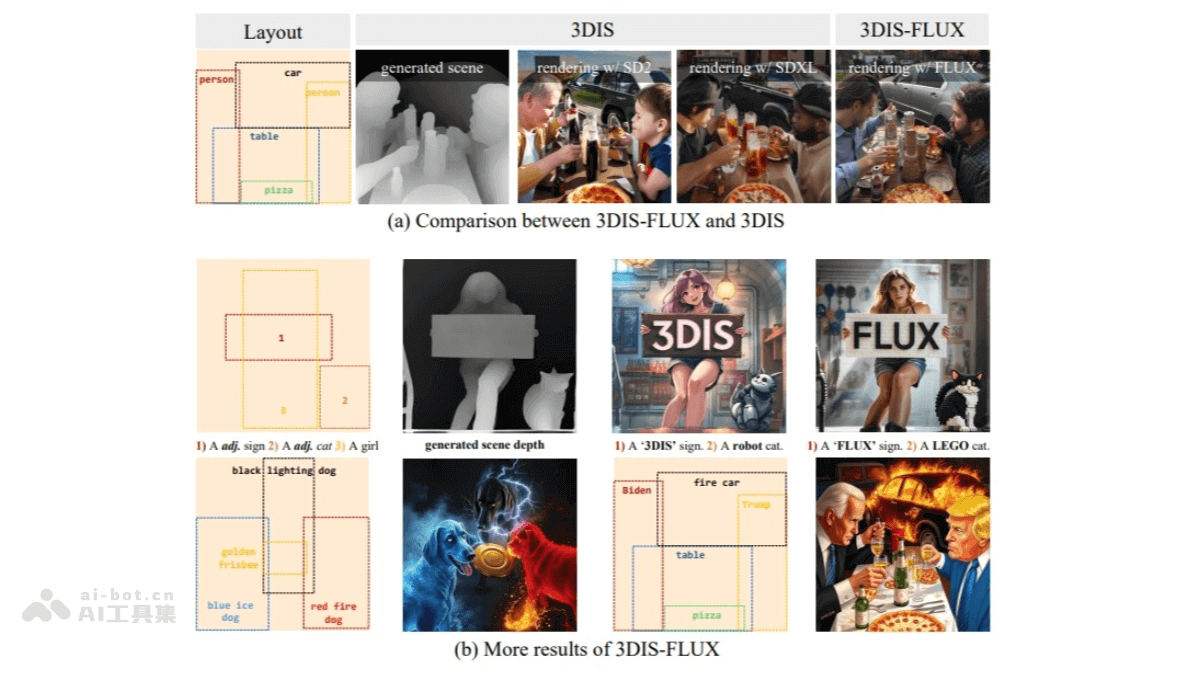
DITTO-2是什么
DITTO-2 是 Adobe 和加州大学研究人员联合推出的新型音乐生成模型,通过优化扩散模型的推理时间,实现快速且可控的音乐生成。模型基于扩散模型的推理时间优化(Inference-Time Optimization, ITO),通过模型蒸馏技术(如一致性模型 Consistency Model, CM 和一致性轨迹模型 Consistency Trajectory Model, CTM),将生成速度提升至比实时更快。DITTO-2 支持多种音乐生成任务,包括音乐修复、扩展、强度控制、旋律控制以及音乐结构控制。还能将无条件扩散模型转换为具有先进文本控制能力的模型,通过最大化 CLAP 分数实现高质量的文本到音乐生成。
DITTO-2的主要功能
音乐修复与扩展:DITTO-2 支持音乐修复(inpainting)和扩展(outpainting),能够对现有音乐片段进行填充或延续。强度控制:用户可以指定音乐的强度变化曲线,例如从低到高或高到低的强度变化。旋律控制:通过输入参考旋律,DITTO-2 能够生成与之匹配的音乐。音乐结构控制:支持对音乐结构的控制,例如定义 A 段和 B 段的时长。文本到音乐生成:DITTO-2 可以将无条件扩散模型转换为具有先进文本控制能力的模型,通过最大化 CLAP 分数实现高质量的文本到音乐生成。高效推理与优化:通过模型蒸馏技术(如一致性模型 CM 和一致性轨迹模型 CTM),DITTO-2 将生成速度提升至比实时更快,同时改善控制粘附性和生成质量。
DITTO-2的技术原理
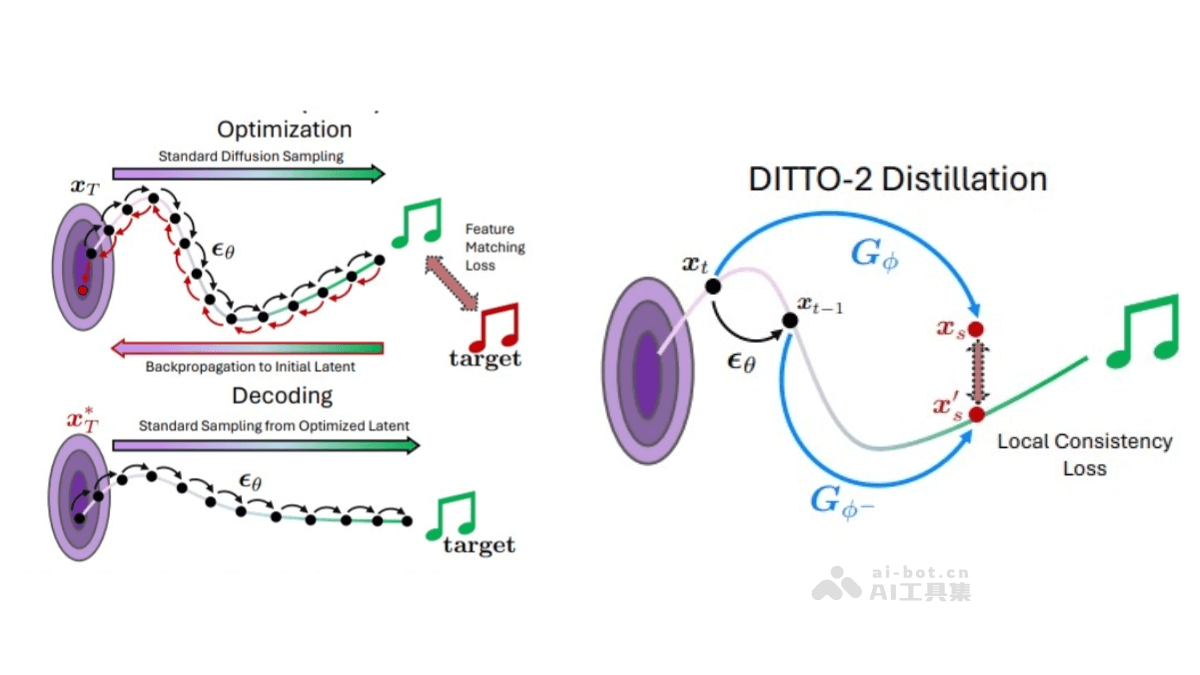
扩散模型蒸馏:DITTO-2 使用了两种模型蒸馏技术:一致性模型(Consistency Model, CM)和一致性轨迹模型(Consistency Trajectory Model, CTM)。CM 将基础扩散模型蒸馏为一个单步采样的新网络,通过最小化学习模型与指数移动平均副本之间的局部一致性损失来训练。CTM 进一步扩展了 CM 的功能,允许在扩散轨迹上的任意两点之间进行跳跃,从而提供更高效的采样路径。推理时间优化(ITO):DITTO-2 通过推理时间优化(Inference-Time Optimization, ITO)在生成过程中实时调整模型状态,更好地符合控制条件或目标。ITO 的核心是优化初始噪声潜在变量,通过特征提取函数、匹配损失函数和优化算法(如梯度下降)来调整模型状态,实现对音乐强度、旋律、结构等的精准控制。代理优化与多步解码:DITTO-2 引入了代理优化(surrogate optimization),将优化过程与最终解码过程分离。优化阶段使用单步采样快速估计噪声潜在变量,解码阶段则通过多步采样生成高质量音乐。这种分离方法在保持快速推理的同时,显著提升了生成音乐的质量。高效训练与应用:DITTO-2 的训练成本较低,仅需在 A100 GPU 上训练 30 多小时。DITTO-2 还支持多种音乐生成任务,包括音乐修复、扩展、强度控制、旋律控制和音乐结构控制。
DITTO-2的项目地址
项目官网:https://ditto-music.github.io/ditto2arXiv技术论文:https://arxiv.org/pdf/2405.20289
DITTO-2的应用场景
音乐创作与生成:DITTO-2 可以通过文本描述生成高质量的音乐。模型能生成符合描述的音乐。实时音乐生成:DITTO-2 的生成速度比实时更快,适合需要快速生成音乐的场景,如实时音乐创作或现场表演。音乐教育工作者和学生:DITTO-2 可以实时生成示例音乐,帮助学生更好地理解和学习音乐理论。教师可以通过输入特定的旋律或和弦结构,快速生成示例音乐,用于教学演示。有声读物和多媒体内容创作者:DITTO-2 支持将文本描述转换为音乐,支持为有声读物、播客或多媒体项目生成背景音乐。